Does Data Skew in PySpark Tasks Cause OOMKilled Due to Python+JVM Memory Usage Exceeding Kubernetes Requests?
Issue description: During PySpark task execution, executor logs show "Kubernetes OOMKilled" with memory usage exceeding Kubernetes limits.
Cause analysis: The memory requested by Kubernetes is calculated based on Spark executor memory multiplied by memoryOverheadFactor. If the data processed by Python is skewed or a single data entry is too large, it may cause memory usage to exceed the memory allocated by Kubernetes.
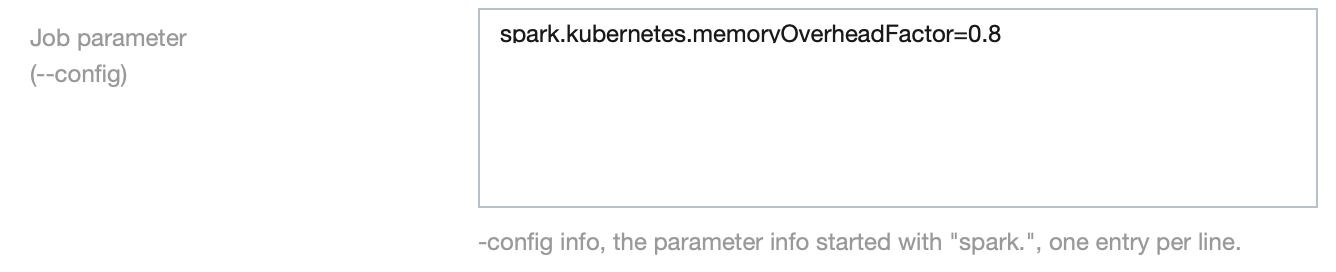
Solution: Add a task parameter spark.kubernetes.memoryOverheadFactor=0.8 with the default value of 0.4.
Operation steps: Go to DLC console and Data Job (Spark Job) > Edit Jobs, then configure as follows:
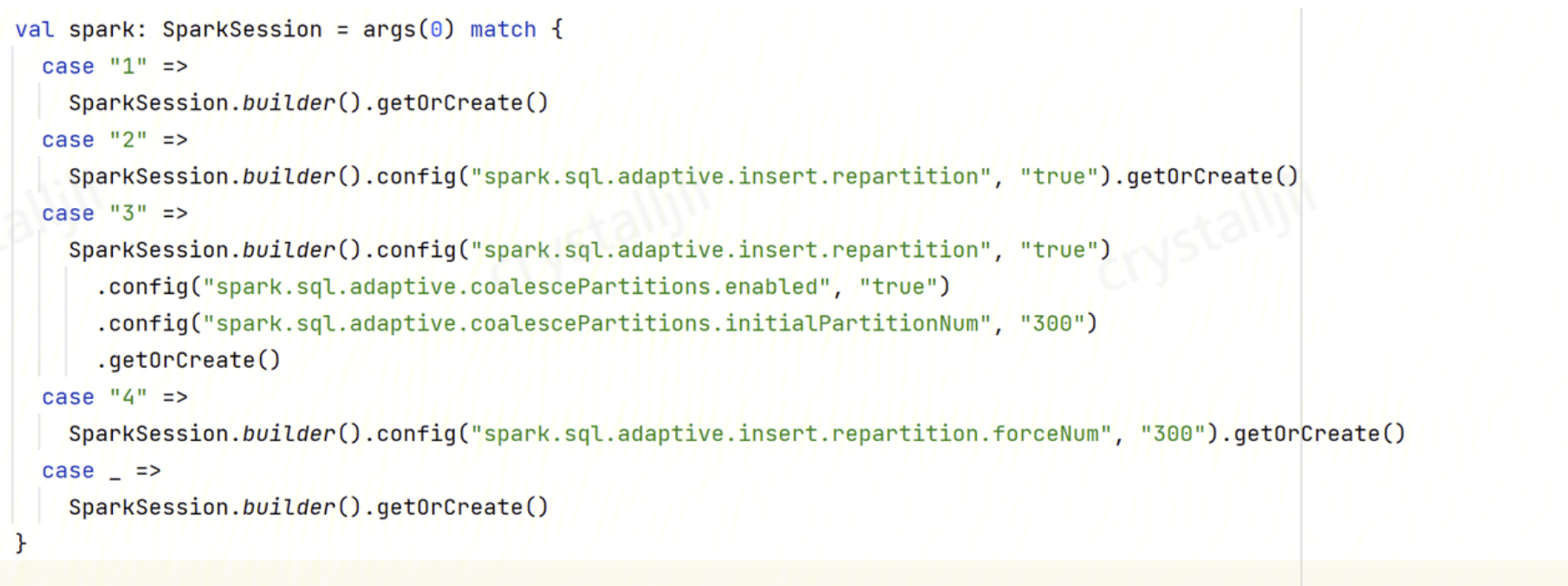
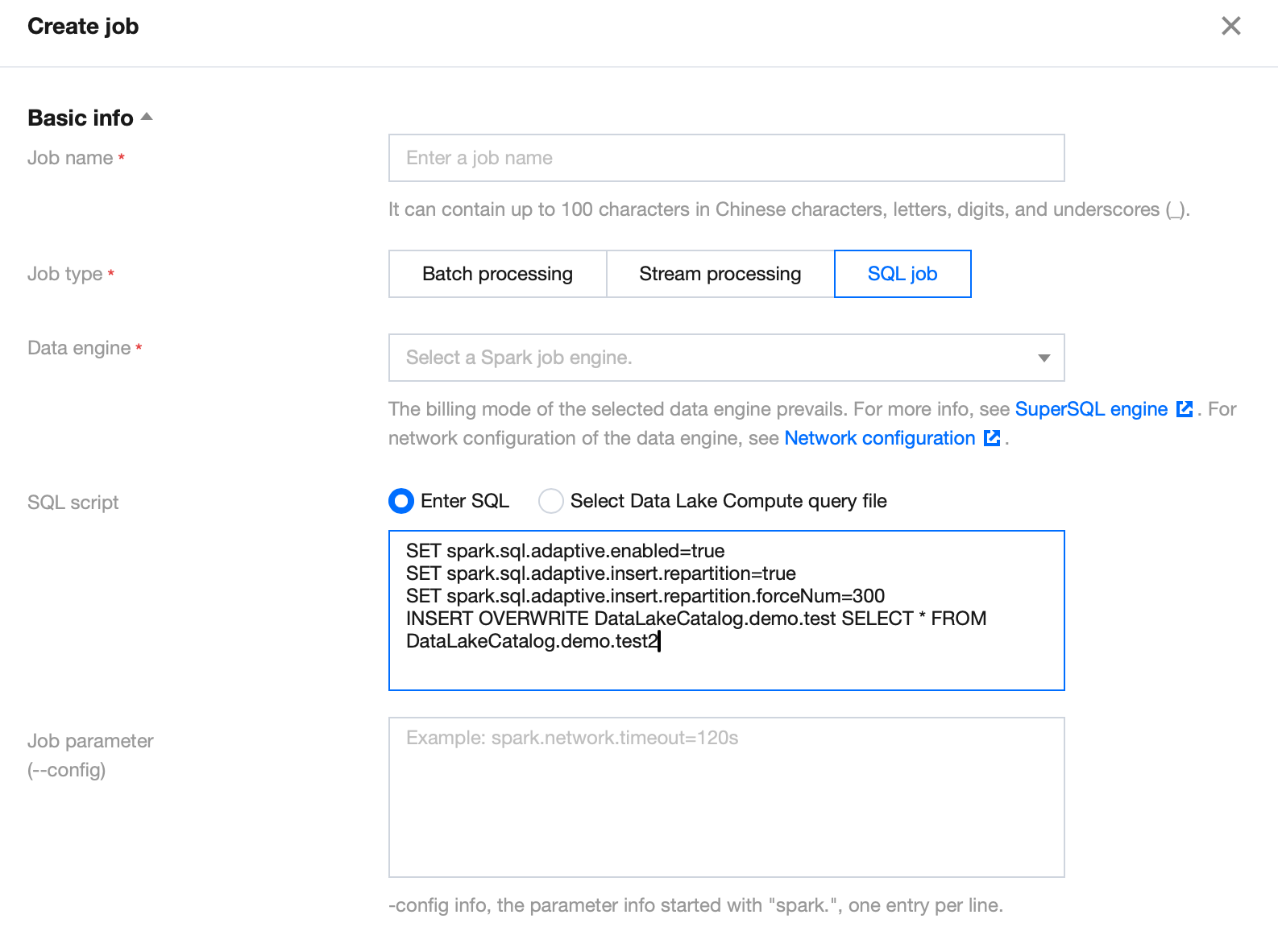
How to Automatically Add a REPARTITION command After INSERT INTO/OVERWRITE for Data Partition to Reduce the Number of Small Files?
Solution: Enable auto repartitioning and configure the following parameters:
Why Do PySpark Tasks Return 503 Errors During High-Concurrency Writes to COS Buckets?
Issue description: During high-concurrency writes to COS buckets by PySpark tasks, executors report frequent 503 errors returned by COS.
Cause: The parallelism for Spark tasks writing to COS is determined by fs.cosn.trsf.fs.ofs.data.transfer.thread.count. For example, without tuning on 4096 cores, the default concurrency is 4096×32=131,072, creating COS bottlenecks.
Solution:
1. Create a metadata-accelerated bucket in COS to prevent rate limiting from frequent list and rename operations during Spark task writes.
2. Adjust bandwidth limits for metadata-accelerated buckets in COS.
3. Add the following parameters to tasks to reduce excessive access pressure on COS during high parallelism.
View SQL execution plans: Use the EXPLAIN keyword in Data Explore to examine physical execution plans. For detailed EXPLAIN usage, refer to EXPLAIN.
View SQL execution logs:
1. SQL execution logs display in the results when running SQL in Data Explore.
2. View SQL execution logs in DLC console > Data Ops > Execution History.
Does Data Write Failure Occur Due to CAST Operations Not Automatically Converting Precision?
Issue description: When migrating Hive SQL to Spark SQL, an error occurred: Cannot safely cast 'class_type': string to bigint.
Cause positioning: Starting from Spark 3.0.0, Spark SQL enforces 3 security policies when performing type conversions:
ANSI: Prohibits Spark from performing certain unreasonable type conversions, for example, 'string' to 'timestamp'.
LEGACY: Allows Spark to force type conversions as long as it's an effective CAST operation.
STRICT: Prohibits Spark from performing any conversion that may damage precision. The default policy is ANSI.
Solution: Switch to the LEGACY policy by setting spark.sql.storeAssignmentPolicy=LEGACY.
An error of 'QUERY_PROGRESS_UPDATE_ERROR(code=3060): Failed to update statement progress'
Issue description: When submitting Spark SQL tasks in Data Explore, the system reports a "Failed to update statement progress" error during execution.
Cause positioning: When multiple Spark SQL tasks are submitted, continuous asynchronous tracking is required for each SQL execution progress. The async processing queue here has a capacity limit, with a default value of 100 (updated to 300 for versions after January 14, 2024). Therefore, if a submitted task remains incomplete while new tasks exceed the queue limit, this error occurs. Such errors typically indicate the SQL task might be a long-tail task. You should evaluate its resource impact on concurrent operations.
Solution: You can adjust the parameter livy.rsc.retained-statements to a value larger than its default in engine configurations. Note that the engine will restart after adjustments. The specific value can be set based on task concurrency. This parameter has minimal impact on the cluster. When concurrent SQL submissions reach 100-200/min, setting this parameter to 6000 was validated through production testing with negligible impact.