適用シーン
Download
フォーカスモード
フォントサイズ
アジャイルでリアルタイムなデータレイク分析
DLCは、ストレージとコンピューティングを分離した大規模データ分析アーキテクチャを採用し、ビッグデータコンポーネントのコンテナ化に基づいて迅速かつ柔軟なデプロイを実現します。クラウドネイティブオブジェクトストレージ方式により無限の拡張が可能で、DLCの先進的なクラウドネイティブ弾性モデルと組み合わせることで、ビジネスの実際の使用曲線に完全に適合し、真のコスト削減を実現します。DLCは、低コストで高弾力性のあるクラウドネイティブデータレイクソリューションにより、企業が統一されたデータ資産を構築し、性能優位性を最大限に発揮させ、ビジネスアプリケーションのアジャイルなイノベーションを促進します。
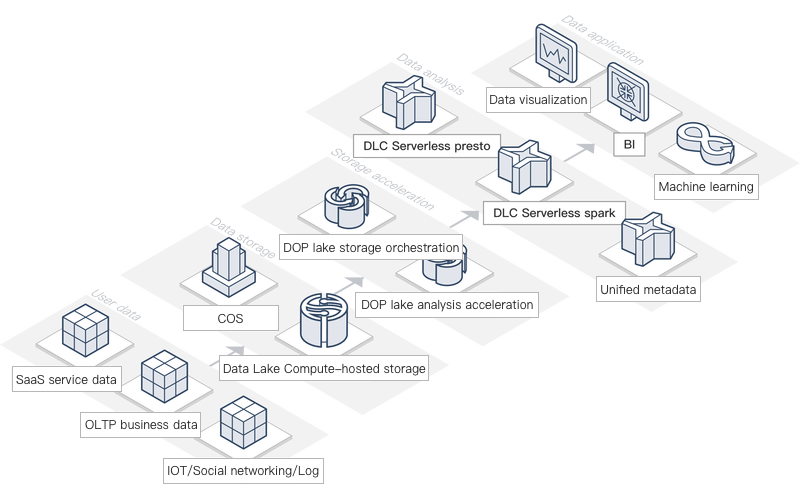
典型シーン
企業ログのバッチクエリ
企業ログデータは通常、jsonやテキストファイルなどの形式で保存されます。ユーザーはログデータをCOSに保存し、標準SQLを使用してCOS内の大規模データを迅速にバッチ分析できます。クエリ結果を素早くデータレポートに変換し、データの可視化を簡単に実現することで、作業効率を大幅に向上させます。同時に、DLCではいくつかの簡単な設定を行うだけで、クラウド上のログサービスのデータをDLCにインポートし、迅速に分析を開始できます。
サービス価値
コスト最適化:ストレージとコンピューティングを分離したクラウドネイティブデータレイクアーキテクチャで、使用量に応じた課金によりコスト投入を正確にコントロール。
強力で使いやすい:統一されたSQL構文で、簡単に使い始められ、より速いクエリ速度を実現。
企業のデータ中台の迅速な構築を支援
データレイクコンピューティング(DLC)は、新しいデータアーキテクチャとして、軽量で敏捷性に優れ、使いやすく低コストの閉ループ型ビッグデータ分析機能を提供します。ユーザーはデータレイクが提供する統一メタデータ管理ビューを活用し、データサイロを解消できます。同時に、クラウド上の豊富なビッグデータ製品の強みを組み合わせ、さまざまなデータのリアルタイム分析やオフライン分析シーンに対応し、企業の多様な課題を包括的に解決します。データの迅速でスムーズな流れを通じて、異なるクラウド製品の能力と強みを有機的に組み合わせることで、DLCは企業にとって最適なデータ中台とデータ起動の場として機能します。
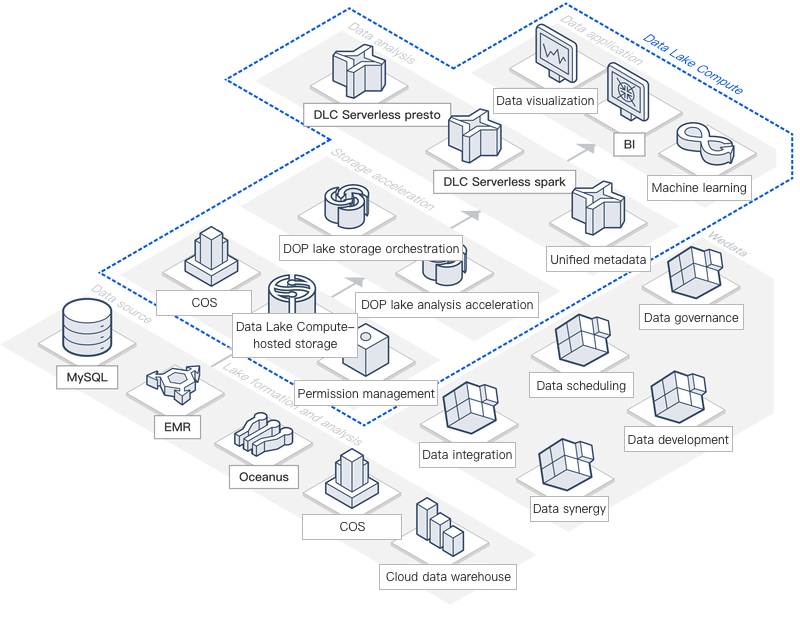
典型的なシナリオ
統一メタデータビュー
ユーザーはクラウド上で複数のメタデータビュー(EMR、DLC、その他各種データソース製品など)を保有している可能性があります。DLCにはエンタープライズレベルの統一メタデータビューが組み込まれており、異なるデータソースのメタデータを一元管理・活用することで、企業のメタデータセンターを迅速に構築し、様々な製品やバージョン間をシームレスに切り替えられます。典型的な例として、同一のメタデータをDLCとEMRの異なる製品間で簡単に切り替えて利用可能です。
データのアジャイルな汎用シナリオ分析
ビッグデータエコシステムにおいて、Prestoは対話型分析に、SparkはETLタスクに優れており、DLCが提供する統一構文と軽量クラスター機能により、同一データを異なるエンジン間でシームレスに切り替え、様々なシナリオに対応できます。またWedataを活用することで、EMR、CDW、ES、データベース、ログサービスなど数十種類のデータ製品やデータソースへのデータインポート/エクスポートが可能となり、データのスムーズな流動を通じて各製品の強みを最大限に発揮できます。
サービス価値
開封即利用:余分な運用保守が不要で、運用コストを削減できます。
メタデータ管理:複数のデータソースをサポートし、統一されたメタデータ管理により、データサイロを解消します。
シーン全カバー:データ分析、アプリケーションシーンを網羅し、データ統合、コラボレーション、スケジューリング、開発、ガバナンスをすべてカバーします。
アジャイルデータレイク連邦分析
DLCは、お客様がデータベースシナリオからビッグデータシナリオへシームレスにアップグレードするのを支援し、オブジェクトストレージ、クラウドデータベース、その他のデータサービスなど、マルチソースの異種データに対する統合クエリ分析をサポートします。ユーザーは統一されたデータビューを使用し、標準SQLでマルチソースデータの連携分析を迅速に実現し、データサイロを解消してデータの価値を引き出すことができます。
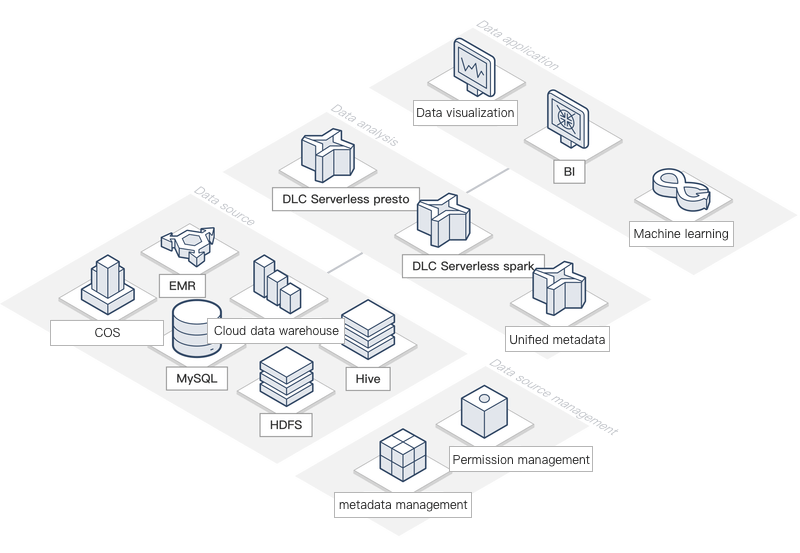
典型シーン
クロスビジネスデータ連携クエリ
企業内の異なる部門や業務ラインは、通常、業務体系に基づいて異なるデータアーキテクチャを採用しており、業務データは異なるストレージシステムに保存され、データの分断が生じています。例えば、トランザクションデータはリレーショナルデータベースに、アクティブデータはRedisに、履歴記録はオブジェクトストレージに保存されます。DLCは、ユーザーが異種データを連携させ、複数のデータソースにまたがる統合分析を可能にし、クロスビジネスデータ分析をより迅速に支援します。
サービス価値
開封即利用:データ転送パイプラインを構築する必要がなく、余分な運用保守も不要で、運用コストを削減できます。
安全で効率的:統一された権限管理システム、データ権限は列レベルまで正確に設定され、究極のクエリ速度を実現。
迅速な利用:プログラミング言語の適応が不要で、簡単にクロスビジネス分析を実現できます。
豊かで多様なデータレイク科学分析
データレイクはAIシナリオにおけるビッグデータ基盤であり、従来の機械学習シナリオや深層学習シナリオでユーザーにサービスを提供します。DLCはさまざまなAI機能とプラットフォームを統合し、迅速に多様な機械学習機能をサポートし、様々なインテリジェントデータレイク分析シナリオで総合的なソリューションを提供します。DLCは複数の業界データをユーザーに無料で開放し、データ取得やクレンジングなしで直接データ分析段階に進むことができます。本製品は強力なBI機能を提供し、ユーザーが予測分析を通じて迅速にデータインサイトを実現できるよう支援します。
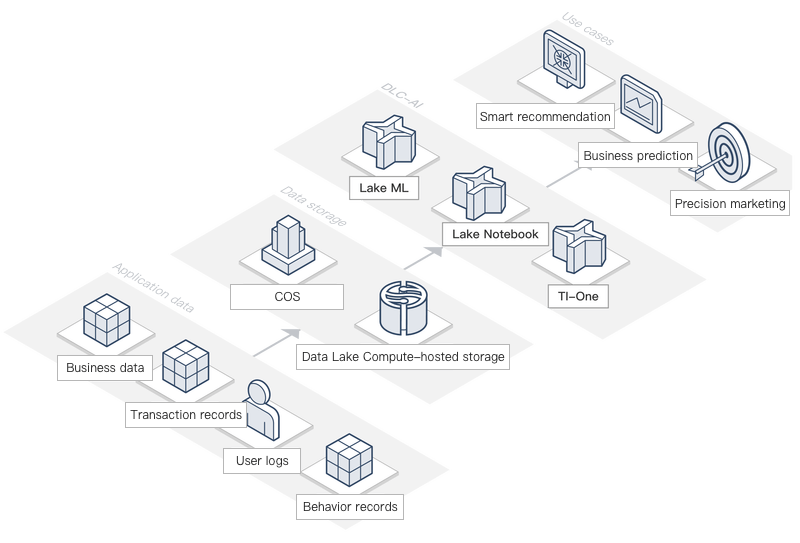
典型シーン
データサイエンスによるビジネス成長の実現
DLCはネイティブの機械学習機能を提供し、成熟した機械学習プラットフォームと融合することで、ユーザーに完善されたインテリジェント分析ソリューションを提供し、スマートレコメンデーションやリコール戦略などの実際のビジネス課題を解決し、企業のビジネス成長を支援します。機械学習シナリオでは、ユーザーはデータ量の多さ、モデルトレーニングの遅さ、アルゴリズムの効果の低さといった課題に直面しています。DLCが提供する機械学習アルゴリズムモデルは即座に利用可能で、ユーザーは迅速にデータに基づいて機械学習モデルを構築し、簡単にビジネス成果を予測できます。DLCはユーザーにBI機能を提供し、企業が効率的なビジネスインテリジェンス分析を実現し、企業の運営効率を向上させることを支援します。
サービス価値
使いやすさが高い:Tencent Cloudの機械学習プラットフォームとシームレスに連携し、さまざまなモデルやAPIを提供して利便性を高めています。
データ規範:データを統一管理・ガバナンスし、データサイエンスに標準化されたデータを提供します。
フィードバック