KV 分离功能概述
Download
聚焦模式
字号
什么是 KV 分离
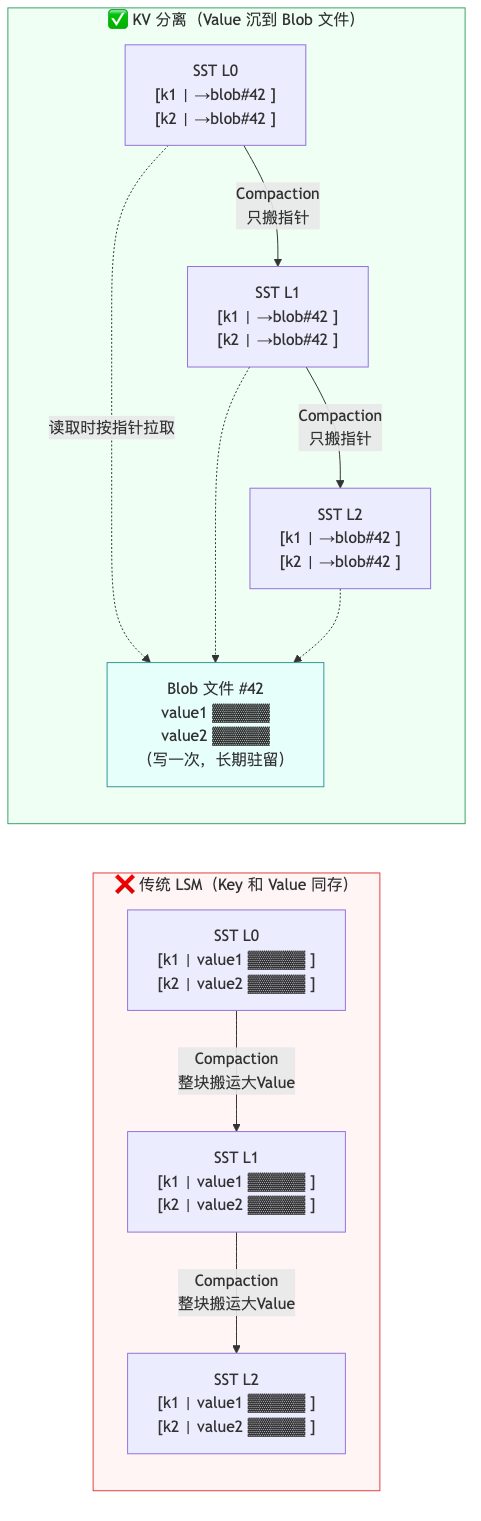
在 LSM-Tree 存储引擎中,键(Key)和值(Value)默认存储在同一个 SST 文件内。当 Value 较大(例如几 KB 到几十 KB 的
TEXT / BLOB / JSON 字段)时,每一次 Compaction 都需要把这些大 Value 反复读出、写入下一层,造成严重的写放大(Write Amplification)。KV 分离的核心思想:当某条记录的 Value 大小超过设定阈值时,把 Value 单独存放到独立的 Blob 文件中,SST 文件中只保留一个指向 Blob 的指针。这样:
SST 文件体积大幅缩小,Compaction 只需搬运指针
大 Value 数据"沉淀"在 Blob 文件中,几乎不参与 Compaction
写放大显著下降,磁盘 I/O 与 SSD 寿命同步受益
数据布局对比
核心收益
收益 | 说明 |
写放大降低 | 大 Value 不再参与 Compaction,整体写放大可下降数倍 |
写吞吐提升 | Compaction 压力下降后,前台写入更平稳,长尾延迟改善 |
SSD 寿命延长 | 总写盘量减少,SSD 磨损降低 |
备份/迁移更高效 | SST 体积变小,Region 迁移、Snapshot 同步更快 |
说明:
标准服务器(CPU 瓶颈):QPS 从18.5K → 21.2K,提升约14%
云盘300MB/s限速(I/O 瓶颈):QPS 从4.2K → 9.2K,提升约118%
在云盘等 I/O 受限场景下,KV 分离收益尤为显著
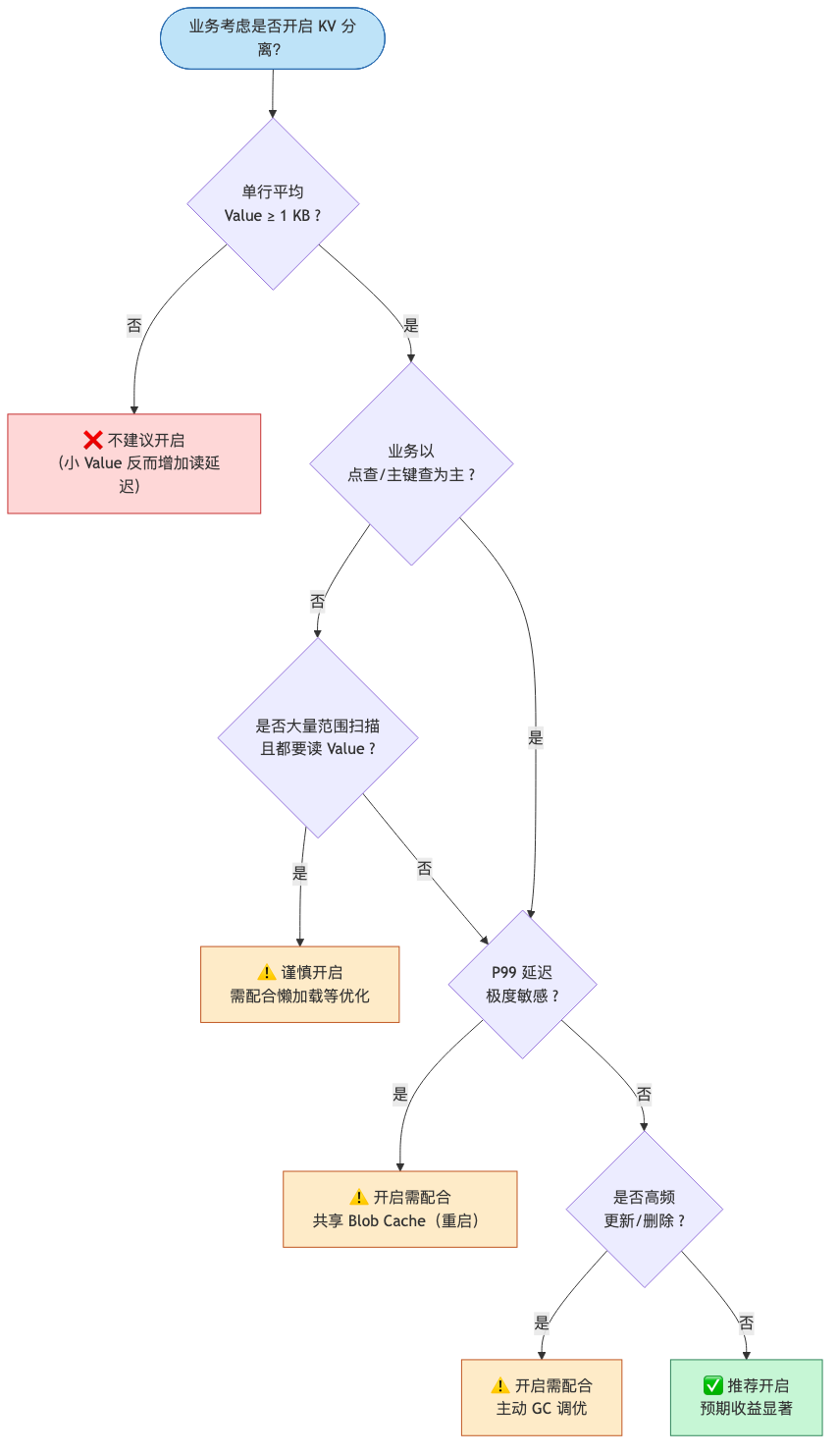
适用与不适用场景
推荐开启 KV 分离的场景:
单行平均 Value 大小 ≥ 1KB,典型如:
富文本、文章正文、聊天消息记录(
TEXT / LONGTEXT)图片缩略图、二进制小附件(
BLOB)大 JSON 文档(用户画像、商品详情、日志聚合)
写多读少,或读取以点查/主键查为主
业务已观察到明显的 Compaction 压力或写放大问题
不建议开启 KV 分离的场景:
大部分 Value 都很小(< 256 B),开启反而带来一次额外的指针解引用,得不偿失
对点查 P99 延迟高度敏感的业务(开启后单次读多一次 Blob 文件 I/O)
大量短生命周期记录(频繁更新/删除),Blob GC 压力较大
范围扫描密集且每条都需要读取 Value 的分析型查询
决策流程图
说明:
建议先在测试环境对照基准压测(启用 vs 关闭),观察写放大、QPS、延迟,再决定是否上生产。
文档反馈