优化器 Hints
Download
聚焦模式
字号
概述
TDSQL 在兼容 MySQL 官方 Hint 标准的基础上,针对分布式并行执行特性扩展了专门的并行 Hint。这些 Hint 主要用于优化器指导,帮助用户更精细地控制查询的并行执行策略,提升复杂查询的性能。
PARALLEL/NO_PARALLEL Hint 并行度控制
PARALLEL Hint 用于指定进行并行扫描(Parallel Scan)的表、并行度和并行扫描方式。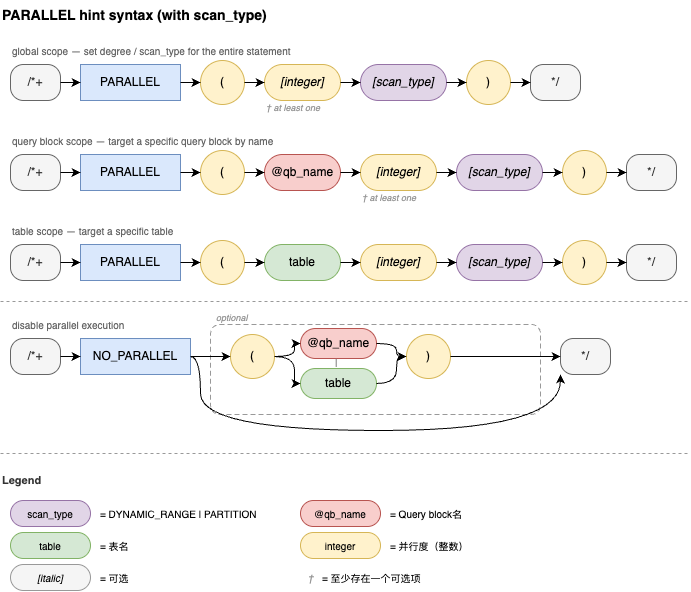
PARALLEL Hint 是一个三层级的 Hint:Global、Query Block、Table。每个级别都可以指定可选的并行度(integer),NO_PARALLEL 用于禁止并行。MySQL 标准 Hint 语法请参见 Optimizer Hints。PARALLEL Hint 还支持在并行度后追加一个可选的扫描策略参数 parallel_scan_type,用于显式声明并行扫描的切分方式,方便在已知数据分布或访问路径特征时获得更稳定的并行执行计划。不指定该参数时由优化器自动选择。三个级别的语义
级别 | 触发条件 | 行为 |
Global 级 | 在主查询中指定,且未给定 query block name 和 table name | integer 作为整个查询的默认并行度。子查询可通过自身的 PARALLEL Hint 覆盖该值。 |
Query Block 级 | 在非主查询中指定,或显式给定 query block name 但未给定 table name | integer 作为该子查询的默认并行度。 |
Table 级 | Hint 中给定了表名 | 若仅给表名而未给 integer,则向上继承(依次为 Query Block 级、Global 级、max_parallel_degree 变量)。若最终未取得并行度(即 max_parallel_degree 为0),则不并行。 |
说明:
Query Block 级和 Global 级(当 Query Block 级未指定时)决定当前 Query Block 是否使用并行计划。例如,指定了
NO_PARALLEL 时,该 Query Block 不会进入并行优化阶段。表级 Hint 仅影响当前表是否进行并行扫描;若 Query Block 和 Global 级未指定 Hint 且 max_parallel_degree 大于0,即使所有表都使用了 NO_PARALLEL,并行优化器仍会选择一个表进行并行扫描。Hint 会强制使用或禁止使用并行,会覆盖
max_parallel_degree 变量,并且不再检查 cost 和 table records 是否满足设置的阈值。示例
-- Global 级别EXPLAIN SELECT /*+ PARALLEL(4) */ * FROM t1 WHERE a > 4;-- Query Block 级别(仅在最顶层查询起作用)EXPLAIN SELECT /*+ QB_NAME(q1) PARALLEL(@q1 4) */ * FROM t1 WHERE a > 4;-- Query Block 级别(仅在子查询中有效)EXPLAIN SELECT * FROM t3 WHERE a = (SELECT /*+ PARALLEL(2) */ COUNT(a) FROM t3);-- Table 级别EXPLAIN SELECT /*+ PARALLEL(t1 4) */ * FROM t1 WHERE a > 4;EXPLAIN SELECT /*+ PARALLEL(t3@q2 4) */ * FROM t3 WHERE a = (SELECT /*+ QB_NAME(q2) */ COUNT(a) FROM t3);EXPLAIN SELECT /*+ PARALLEL(@q2 t3 4) */ * FROM t3 WHERE a = (SELECT /*+ QB_NAME(q2) */ COUNT(a) FROM t3);
PARALLEL Hint 与固定查询计划结合,可以在不修改语句的情况下,对特定语句开启并行:CALL dbms_admin.statement_outline_add_rule('test', 'select /*+ PARALLEL(4) */ sum(c),b from t1 group by b');
并行扫描策略
PARALLEL Hint 的参数列表末尾可追加一个可选的 parallel_scan_type,用于声明并行扫描的切分策略。语法形式如下:/*+ PARALLEL([@query_block | tbl_name] [integer] [parallel_scan_type]) *//*+ PARALLEL(parallel_scan_type) *//*+ PARALLEL(@query_block parallel_scan_type) */
parallel_scan_type 的可选取值如下表所示:取值 | 适用对象 | 说明 |
DYNAMIC_RANGE | 分区表、非分区表 | 基于索引或主键的连续范围进行动态切分,由各 Worker 在执行期动态获取尚未扫描的子区间。适用于数据量较大、访问路径为索引范围扫描或全表扫描的场景。 |
PARTITION | 仅分区表 | 按分区切分,每个 Worker 负责一个或多个分区的扫描。实际并行度自动取并行度参数与分区数中的较小值。仅适用于分区表,对非分区表使用时优化器会自动忽略该策略。 |
说明:
不指定
parallel_scan_type 时,由优化器根据表类型、访问路径和代价自动选择并行扫描策略,原有 PARALLEL(n) 写法的语义保持不变。parallel_scan_type 仅影响并行扫描的切分方式,不改变 PARALLEL Hint 三个级别(Global、Query Block、Table)的并行度生效规则。当通过 Hint 指定
PARTITION 但目标表非分区表时,该策略对当前表不生效,优化器会回退到其他可行的并行扫描策略。示例:
-- Global 级:仅声明扫描策略,由优化器使用默认或会话级并行度EXPLAIN SELECT /*+ PARALLEL(DYNAMIC_RANGE) */ * FROM t1 WHERE a > 4;-- Global 级:同时指定并行度与扫描策略EXPLAIN SELECT /*+ PARALLEL(4 DYNAMIC_RANGE) */ * FROM t1 WHERE a > 4;-- Query Block 级:在指定查询块内启用按分区并行扫描EXPLAIN SELECT /*+ QB_NAME(q1) PARALLEL(@q1 4 PARTITION) */ *FROM t_partitioned WHERE created_date >= '2024-01-01';-- Table 级:仅对分区表 t_part 启用按分区并行扫描EXPLAIN SELECT /*+ PARALLEL(t_part 8 PARTITION) */ *FROM t_part JOIN t1 ON t_part.id = t1.id;-- Table 级:仅对表 t1 指定动态范围切分,并继承上层并行度EXPLAIN SELECT /*+ PARALLEL(t1 DYNAMIC_RANGE) */ * FROM t1 WHERE a > 4;
PQ_DISTRIBUTE Hint 数据分布策略
PQ_DISTRIBUTE 用于指示并行查询优化器如何在查询计划中添加数据重分布操作,以及 GROUP BY、ORDER BY 和窗口函数(WINDOW)的并行执行策略。语法如下: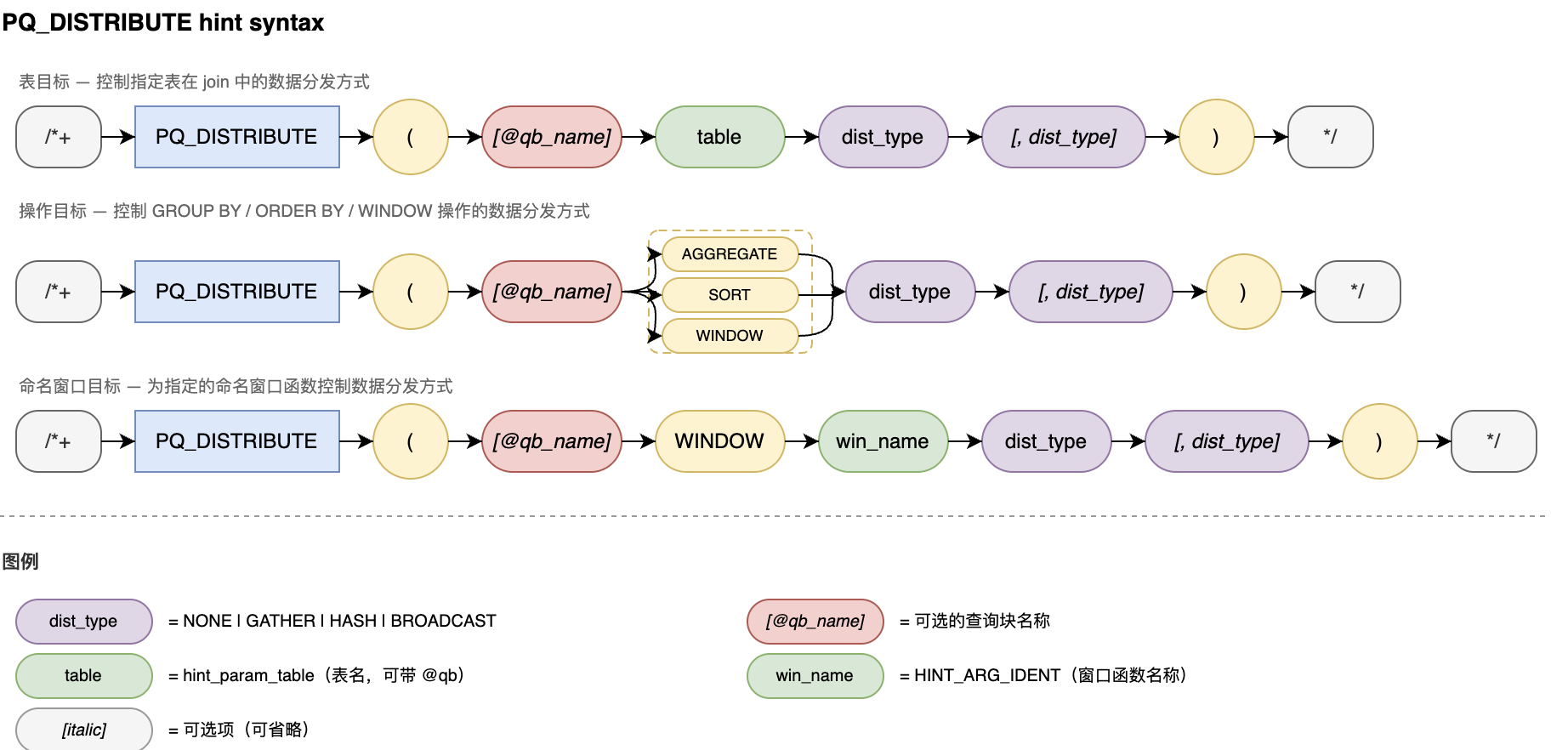
dist_type 语义说明
Table target(表目标)
写法 | 含义 |
PQ_DISTRIBUTE(t1 NONE) | 单个 dist_type:控制本表分发。NONE = 不重分布(保持本地数据) |
PQ_DISTRIBUTE(t1 GATHER) | 单个 dist_type:控制本表分发。GATHER = 添加 collector(汇聚到 leader) |
PQ_DISTRIBUTE(t1 d1, d2) | 两个 dist_type:第一个 = 对端表(join 另一侧),第二个 = 本表。各取值同上 |
说明:
目前仅 NONE 和 GATHER 实际生效;HASH / BROADCAST 可解析但会被视为 unspecified
Operation target(操作目标:AGGREGATE / SORT / WINDOW)
写法 | 含义 |
PQ_DISTRIBUTE(AGGREGATE GATHER) | 单阶段聚合:先将所有数据 gather 到 leader,再做聚合 |
PQ_DISTRIBUTE(AGGREGATE NONE) | 下推单阶段聚合:在各 worker 上直接聚合,不做数据重分布 |
PQ_DISTRIBUTE(AGGREGATE NONE, GATHER) | 两阶段聚合:worker 做局部聚合 → gather → leader 做最终聚合 |
PQ_DISTRIBUTE(SORT GATHER) | 不下推排序:先将所有数据 gather 到 leader,再做排序 |
PQ_DISTRIBUTE(SORT NONE, GATHER) | 下推排序:worker 做局部排序 → gather → leader 做归并排序 |
语法
/*+ PQ_DISTRIBUTE([@query_block] target dist_type[, dist_type]) */
其中
target 有三种类型:目标类型 | 语法形式 | 说明 |
表目标 | PQ_DISTRIBUTE([@qb] tbl_name dist_type[, dist_type]) | 控制表在 Join 中的数据分布方式 |
操作目标 | PQ_DISTRIBUTE([@qb] AGGREGATE|SORT dist_type[, dist_type]) | 控制聚合或排序操作的并行策略 |
命名窗口目标 | PQ_DISTRIBUTE([@qb] WINDOW win_name dist_type[, dist_type]) | 控制指定命名窗口函数的并行策略 |
@qb 为可选的 query block 名称(如 @qb1),用于指定 Hint 作用的查询块。dist_type 可选值为:NONE、GATHER。其中 HASH 和 BROADCAST 目前未生效,会被视为未指定。表目标语义
当
target 为表名时,Hint 控制该表在 Join 操作中的数据分布方式。写法 | 含义 |
PQ_DISTRIBUTE(t1 NONE) | 表 t1 不添加 Collector(数据留在各 Worker 上) |
PQ_DISTRIBUTE(t1 GATHER) | 表 t1 添加 Collector(数据汇聚到 Leader) |
PQ_DISTRIBUTE(t1 d1, d2) | d1 控制 Join 对端的分布方式,d2 控制本表(t1)的分布方式 |
当指定两个
dist_type 时,第一个参数 d1 作用于 Join 的对端表,第二个参数 d2 作用于本表。例如:-- t1 不添加 Collector(留在 Worker),Join 对端添加 Collector(汇聚到 Leader)SELECT /*+ PQ_DISTRIBUTE(t1 GATHER, NONE) */ * FROM t1 JOIN t2 ON t1.id = t2.id;
操作目标语义
当
target 为 AGGREGATE 或 SORT 时,Hint 控制聚合或排序操作的并行执行策略。聚合(AGGREGATE)
写法 | 含义 |
PQ_DISTRIBUTE(AGGREGATE GATHER) | 单阶段聚合:各 Worker 数据汇聚到 Leader 后执行聚合 |
PQ_DISTRIBUTE(AGGREGATE NONE) | 下推单阶段聚合:各 Worker 上直接执行完整聚合(无需重分布) |
PQ_DISTRIBUTE(AGGREGATE NONE, GATHER) | 两阶段聚合:各 Worker 先执行部分聚合,再汇聚到 Leader 执行最终聚合 |
-- 完全下推的一阶段聚合SELECT /*+ PQ_DISTRIBUTE(AGGREGATE NONE) */department, AVG(salary)FROM employeesGROUP BY department;-- Worker 和 Leader 二阶段聚合SELECT /*+ PQ_DISTRIBUTE(AGGREGATE NONE, GATHER) */department, AVG(salary)FROM employeesGROUP BY department;-- 只在 Leader 上执行的一阶段聚合SELECT /*+ PQ_DISTRIBUTE(AGGREGATE GATHER) */department, AVG(salary)FROM employeesGROUP BY department;
排序(SORT)
写法 | 含义 |
PQ_DISTRIBUTE(SORT GATHER) | 非下推排序:各 Worker 数据汇聚到 Leader 后执行排序 |
PQ_DISTRIBUTE(SORT NONE, GATHER) | 下推排序:各 Worker 先执行局部排序,再汇聚到 Leader 执行归并排序 |
-- Worker 局部排序 + Leader 归并排序SELECT /*+ PQ_DISTRIBUTE(SORT NONE, GATHER) */ *FROM large_tableORDER BY create_time DESC;-- 只在 Leader 上全局排序SELECT /*+ PQ_DISTRIBUTE(SORT GATHER) */ *FROM large_tableORDER BY create_time DESC;
命名窗口目标语义
当
target 为 WINDOW win_name 时,Hint 控制指定命名窗口函数的并行策略,语义与 SORT 类似。SELECT /*+ PQ_DISTRIBUTE(WINDOW w NONE, GATHER) */ SUM(val) OVER wFROM t1 WINDOW w AS (ORDER BY id);
示例
-- 表目标:控制 t1 在 Join 中不添加 CollectorSELECT /*+ PQ_DISTRIBUTE(t1 NONE) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- 表目标(指定 query block):t1 添加 Collector,对端不添加SELECT /*+ PQ_DISTRIBUTE(@qb1 t1 NONE, GATHER) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- 操作目标:使用两阶段聚合SELECT /*+ PQ_DISTRIBUTE(AGGREGATE NONE, GATHER) */ dept, SUM(salary) FROM emp GROUP BY dept;-- 操作目标:下推排序SELECT /*+ PQ_DISTRIBUTE(SORT NONE, GATHER) */ * FROM t1 ORDER BY col1;-- 组合使用:同时指定表分布和聚合策略SELECT /*+ PQ_DISTRIBUTE(t1 NONE) PQ_DISTRIBUTE(AGGREGATE NONE, GATHER) */ dept, COUNT(*) FROM t1 GROUP BY dept;
说明:
1.
HASH 和 BROADCAST 作为 dist_type 值目前暂不支持,使用时会被视为未指定(等同于不写该 Hint)。2. 当仅指定一个
dist_type 用于表目标时,它控制本表的分布方式,JOIN 对端不受约束。3. 当指定两个
dist_type 用于表目标时,第一个参数控制对端,第二个参数控制本表。4. Hint 仅在并行查询(Parallel Query)开启时生效。
5. 多个
PQ_DISTRIBUTE Hint 可在同一条 SQL 中组合使用,分别控制不同目标。SUBQUERY Hint 子查询并行策略
PQ_PRE_EVALUATION:指定子查询在引用它的父查询执行之前提前执行,并行 Worker 之间直接读取子查询结果。
PQ_INLINE_EVALUATION:强制不提前执行子查询,也就是按 MySQL 的逻辑根据父查询的需要按需执行。
示例:
-- 指定这个 IN 子查询使用 MATERIALIZATION 策略并且在并行计划不使用预先执行策略EXPLAIN FORMAT=TREESELECT * FROM t1WHERE t1.a IN (SELECT /*+ SUBQUERY(MATERIALIZATION, PQ_INLINE_EVALUATION) */ aFROM t2);-- 指定 Derived Table 子查询 t 使用预先执行策略EXPLAIN FORMAT=TREESELECT /*+ NO_MERGE(t) PQ_DISTRIBUTE(t1 NONE) */ t1.aFROM t1, (SELECT /*+ SUBQUERY(PQ_INLINE EVALUATION) */ aFROM t2) tWHERE t1.a = t.a;
SET_VAR 方式
通过
SET_VAR Hint 在单条 SQL 中临时修改变量值,无需全局或会话级 SET:-- 临时降低阈值,让本查询走并行SELECT /*+ SET_VAR(parallel_scan_records_threshold=1000) */ * FROM t1;-- 临时开启 Parallel Hash JoinSELECT /*+ SET_VAR(tdsql_enable_parallel_hash_join=ON) */* FROM t1, t2 WHERE t1.b = t2.b;
文档反馈