テーブル作成の実践
Download
フォーカスモード
フォントサイズ
DLCデータレイクコンピューティングは、ネイティブテーブル(Iceberg)や外部テーブルなど、さまざまなシナリオでのテーブル作成をサポートしています。具体的なテーブル作成の実践ケースについては、以下の事例を参照してください。
ネイティブテーブル(Iceberg)の作成
Spark ETL テーブル作成シナリオ
適用対象:周期的に insert into、insert overwrite、merge into などのバッチジョブ操作を実行する場合。
/**デフォルトはcopy-on-writeモードです。どちらのモードかわからない場合は、設定する必要はなく、copy-on-writeモードを使用してください。merge-on-readは行レベルの更新シナリオに大きな最適化があります。copy-on-writeの適応シーン:クエリ性能が比較的速く、書き込みが比較的遅いため、定期的なETLタスクや大量のデータを一括更新する操作シーンに適しています。merge-on-readの適応シーン:クエリ性能が比較的やや遅く、書き込みが速いため、書き込み性能が要求されるシーンに適しています。行レベルの更新能力に優れており、頻繁な小範囲(<10%)のmerge into/update/deleteやOceanus(Flinkストリーミング書き込みシーン)の書き込み性能が大幅に向上します。*//** コピーオンライトテーブル */CREATE TABLE dlc_db.iceberg_etl (id INT,name string,age INT) TBLPROPERTIES ('format-version' = '2','write.metadata.previous-versions-max' = '100','write.metadata.delete-after-commit.enabled' = 'true');/** 読み取り時にマージするテーブル */CREATE TABLE dlc_db.iceberg_etl (id INT,name string,age INT) TBLPROPERTIES ('format-version' = '2','write.metadata.previous-versions-max' = '100','write.metadata.delete-after-commit.enabled' = 'true','write.update.mode' = 'merge-on-read','write.merge.mode' = 'merge-on-read','write.delete.mode' = 'merge-on-read');
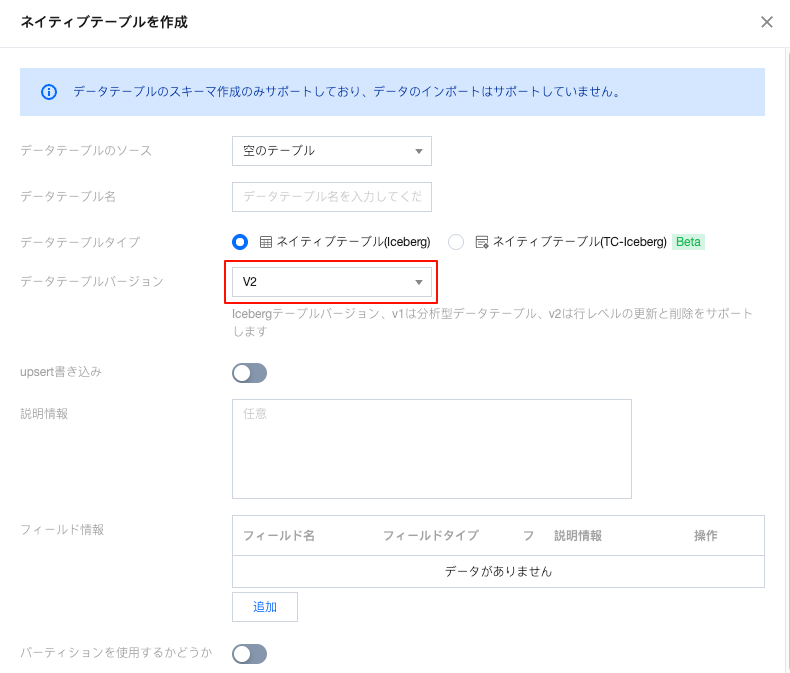
コンソール作成:copy-on-write モード
1. クリックしてネイティブテーブルを作成します。
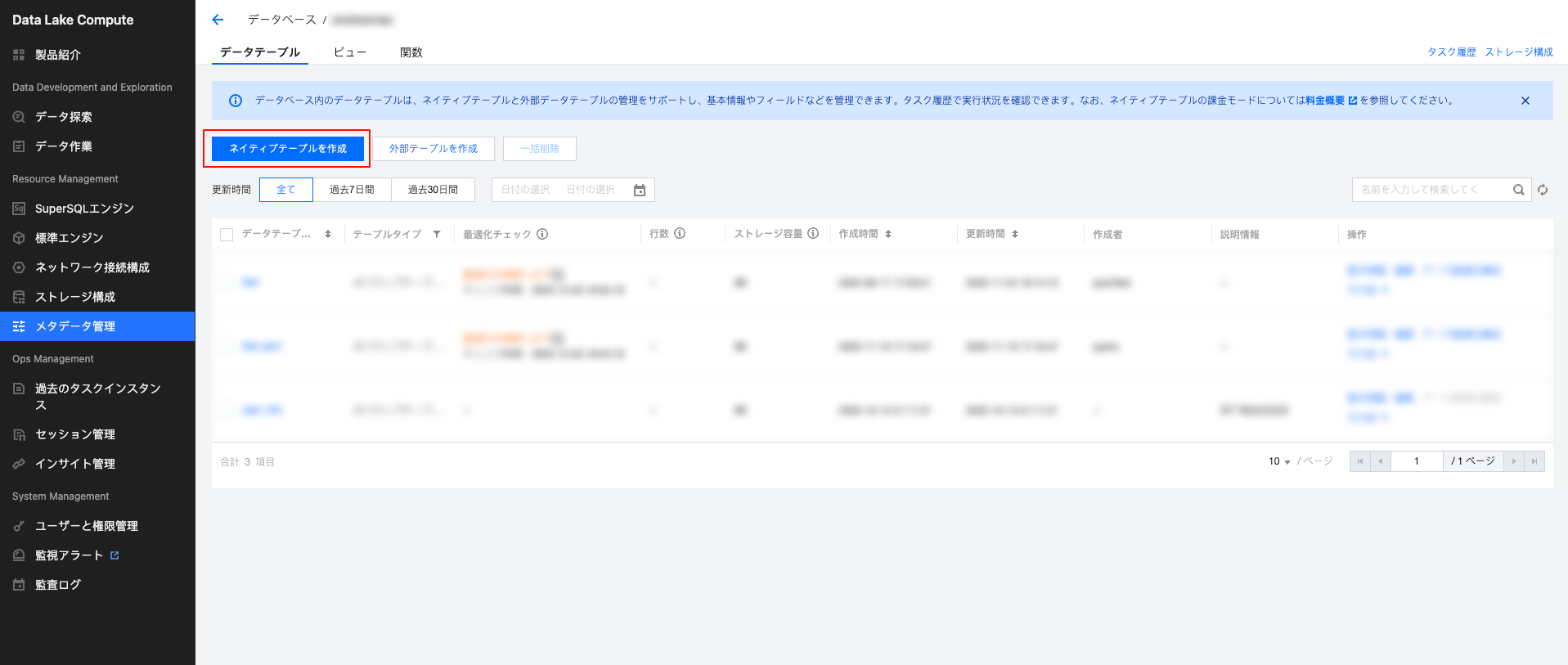
2. データテーブルのバージョンを選択します。
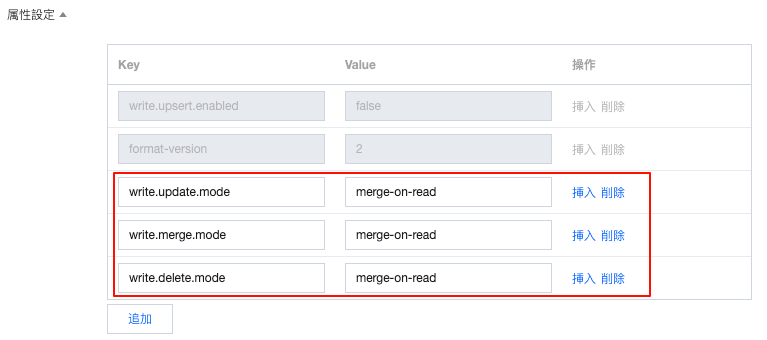
コンソールで作成:merge-on-readモード(追加で3つの属性値を設定する必要があります)
Flink ストリーミング書き込みシナリオ
適用範囲:Oceanus(Flink ストリーミング書き込み)シナリオ。
/** flink ストリーミング書き込み主キーは id */CREATE TABLE dlc_db.iceberg_cdc_by_id (id INT,name string,age INT) TBLPROPERTIES ('format-version' = '2','write.metadata.previous-versions-max' = '100','write.metadata.delete-after-commit.enabled' = 'true','write.upsert.enabled' = 'true','write.update.mode' = 'merge-on-read','write.merge.mode' = 'merge-on-read','write.delete.mode' = 'merge-on-read','write.distribution-mode' = 'hash','write.parquet.bloom-filter-enabled.column.id' = 'true','dlc.ao.data.govern.sorted.keys' = 'id');/** flink ストリーミング書き込みの主キーは id,name の複合主キーです */CREATE TABLE dlc_db.iceberg_cdc_by_id_and_name (id INT,name string,age INT) TBLPROPERTIES ('format-version' = '2','write.metadata.previous-versions-max' = '100','write.metadata.delete-after-commit.enabled' = 'true','write.upsert.enabled' = 'true','write.update.mode' = 'merge-on-read','write.merge.mode' = 'merge-on-read','write.delete.mode' = 'merge-on-read','write.distribution-mode' = 'hash','write.parquet.bloom-filter-enabled.column.id' = 'true','write.parquet.bloom-filter-enabled.column.name' = 'true','dlc.ao.data.govern.sorted.keys' = 'id,name');
コンソール作成:主キーがidのテーブル
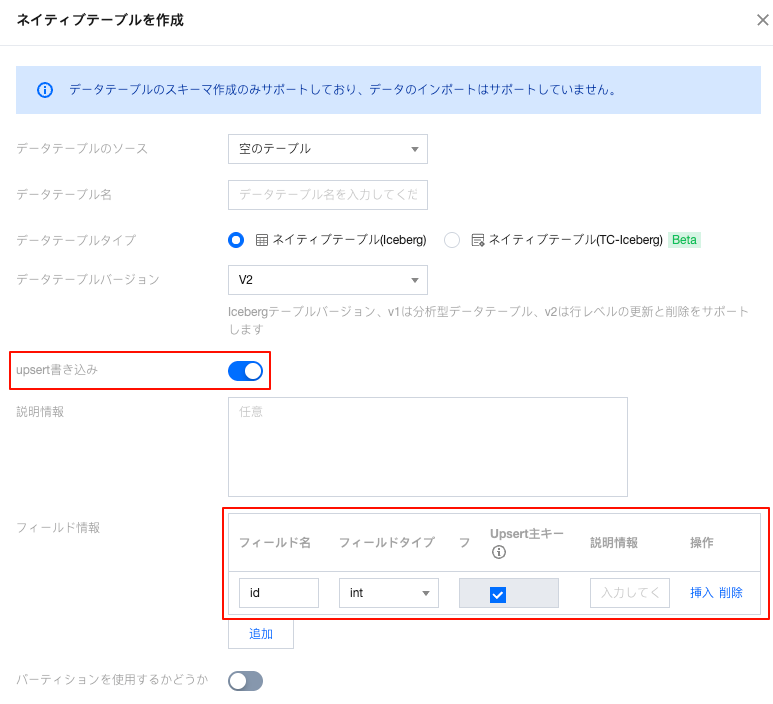
設定説明
属性値 | 意味 | 設定ガイド |
format-version | Icebergテーブルバージョン、取り得る値は1、2。 標準エンジン Spark Standard-S 1.1、SuperSQL Spark 3.5 のデフォルト値は2で、それ以外のシナリオではデフォルト値は1です。 | 2に設定することをお勧めします |
write.upsert.enabled | upsertをオンにするかどうか、値はtrueです。設定しない場合はオフになります。 | ユーザーの書き込みシナリオにupsertがある場合、trueに設定する必要があります。 |
write.update.mode | 更新モード | デフォルトはコピーオンライトです デフォルトはcopy-on-writeモードです。2つのモードが不明確な場合は、copy-on-writeモードを使用してください。merge-on-readは行レベルの更新シナリオに大きな最適化があります。 コピーオンライトの適応シナリオ:クエリ性能が比較的速く、書き込みが比較的遅いため、定期的なETLタスクや大量データのバッチ更新操作シーンに適しています。 merge-on-readの適応シナリオ:クエリ性能はやや遅めですが、書き込みはより高速で、書き込み性能が求められる場面に適しています。行単位の更新能力に優れており、頻繁な小範囲(10%未満)のmerge into/update/deleteやOceanus(Flinkストリーム書き込みシナリオ)での書き込み性能が大幅に向上します。 |
write.merge.mode | マージモード | デフォルトはcopy-on-writeです デフォルトはcopy-on-writeモードです。2つのモードが不明確な場合は、copy-on-writeモードを使用してください。merge-on-readは行レベルの更新シナリオに大きな最適化があります。 コピーオンライトの適応シナリオ:クエリ性能が比較的速く、書き込みが比較的遅いため、定期的なETLタスクや大量データのバッチ更新操作シーンに適しています。 merge-on-readの適応シナリオ:クエリ性能はやや遅めですが、書き込みはより高速で、書き込み性能が求められる場面に適しています。行単位の更新能力に優れており、頻繁な小範囲(10%未満)のmerge into/update/deleteやOceanus(Flinkストリーム書き込みシナリオ)での書き込み性能が大幅に向上します。 |
write.parquet.bloom-filter-enabled.column.{col} | Oceanus(Flinkストリーム書き込み)シナリオ専用で、bloomをオンにします。値がtrueの場合はオンになり、デフォルトではオフです。 | Flinkストリーム書き込みシナリオでは必ず有効にする必要があり、上流の主キーに基づいて設定する必要があります。上流に複数の主キーがある場合、最大で最初の2つまで使用されます。有効にすると、MORクエリと小ファイルマージのパフォーマンスが向上します。 |
write.distribution-mode | 書き込みモード | 値がhashの場合、データ書き込み時に自動的に再パーティションが行われますが、一部の書き込み性能に影響を与えるため、デフォルトの動作を維持することをお勧めします。 Flinkストリーム書き込みシナリオでは、hashに設定することをお勧めします。書き込み性能を最適化できます。他のシナリオでは、設定せずにデフォルト値を維持することをお勧めします。 |
write.metadata.delete-after-commit.enabled | メタデータファイルの自動クリーンアップを開始 | trueに設定することを強くお勧めします。有効にすると、Icebergはスナップショット生成時に古いmetadataファイルを自動的にクリーンアップし、大量のmetadataファイルの蓄積を防ぐことができます。 |
write.metadata.previous-versions-max | デフォルトで保持するmetadataファイルの数を設定する | デフォルト値は100です。特定の状況下では、ユーザーはこの値を適切に調整することができますが、write.metadata.delete-after-commit.enabledと併用する必要があります。 |
外部テーブル作成
CSV形式の外部テーブル作成
/**1. separatorChar: 区切り文字、デフォルトは , 。CSVファイル内のフィールド間の区切り文字を指定し、Hiveが各行のフィールドを正しく解析できるようにします。1. 引用文字、デフォルトは「"」です。元のファイルに引用文字がない場合は、デフォルト値を使用できます。引用文字の役割は、区切り文字(カンマなど)や改行を含むフィールドを処理するのに役立ちます。例えば、column1フィールドの値「x1,x2」が二重引用符「"x1,x2"」で囲まれている場合、誤って2つの独立したフィールドとして解析されることはありません。1. LOCATION: 対応するcos上のストレージパスに変更する必要があります1. TBLPROPERTIES の skip.header.line.count テーブルプロパティ:デフォルトは0で、1を設定すると1行スキップします。このプロパティは、ファイルを読み取るときにスキップするヘッダー行数を指定するために使用されます。多くのcsvファイルのヘッダーには通常、実際のデータではなく列名が含まれているためです。*/CREATE EXTERNAL TABLE IF NOT EXISTS dlc_db.`csv_tb`(`id` int,`name` string)ROW FORMAT SERDE'org.apache.hadoop.hive.serde2.OpenCSVSerde'WITH SERDEPROPERTIES ('quoteChar'='"','separatorChar'=',')STORED AS INPUTFORMAT'org.apache.hadoop.mapred.TextInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'LOCATION'cosn://your_cos_location'TBLPROPERTIES ('skip.header.line.count'='1');
コンソールでの作成
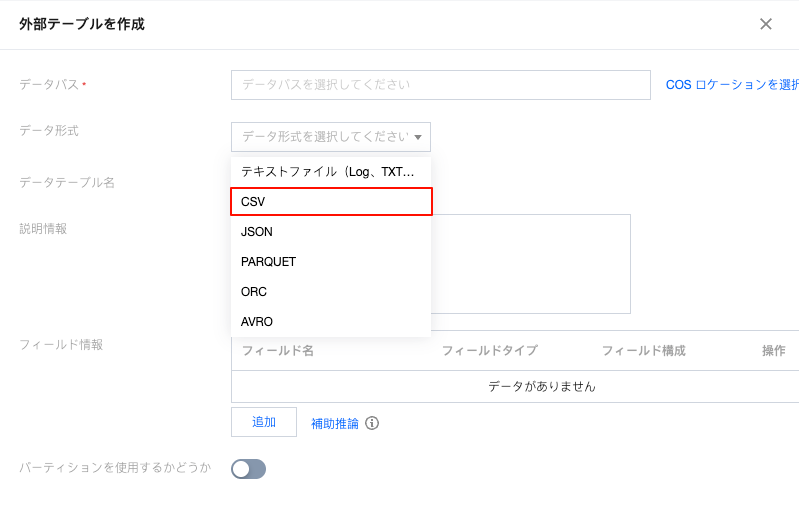
json形式の外部テーブルを作成
/**LOCATION: 対応するcosストレージディレクトリを指し、その他はそのまま保持します*/CREATE EXTERNAL TABLE IF NOT EXISTS dlc_db.json_demo(`id` bigint, `name` string)ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'STORED AS TEXTFILELOCATION 'cosn://your_cos_location'
jsonファイルの内容例、各行は独立したjson文字列です:
{"id":1,"name":"tom"}{"id":2,"name":"tony"}
parquet形式の外部テーブルを作成
/**LOCATION: 対応するcosストレージディレクトリを指し、その他はそのまま保持します*/CREATE EXTERNAL TABLE IF NOT EXISTS dlc_db.parquet_demo(`id` int, `name` string)PARTITIONED BY (`dt` string)STORED AS PARQUET LOCATION 'cosn://your_cos_location';
ORC形式の外部テーブルを作成します
/**LOCATION: 対応するcosストレージディレクトリを指し、その他はそのまま保持します*/CREATE EXTERNAL TABLE IF NOT EXISTS dlc_db.orc_demo(`id` int,`name` string)PARTITIONED BY (`dt` string)STORED AS ORC LOCATION 'cosn://your_cos_location'
AVRO形式の外部テーブルを作成
/**LOCATION: 対応するcosストレージディレクトリを指し、その他はそのまま保持します*/CREATE EXTERNAL TABLE IF NOT EXISTS dlc_db.avro_demo(`id` int,`name` string)PARTITIONED BY (`dt` string)STORED AS ORC LOCATION 'cosn://your_cos_location'
補足
列タイプとパーティション列
CREATE TABLE パラメータセクションを参照してください。
注意:
バイナリタイプのフィールド binary は、select クエリを実行する際に以下のようなエラーが発生する可能性があります。原因は、エンジンがデフォルトで結果セットを csv ファイルに書き込むため、バイナリデータを csv ファイルに書き込むことは現在サポートされていません。

解決方法(タスクレベルでの設定に対応):
1. 保存結果のファイル形式を変更: kyuubi.operation.result.saveToFile.format=parquet (保存ファイル形式を設定、オプション: parquet, orc)。
2. 設定を変更し、結果をcosに保存しない: kyuubi.operation.result.saveToFile.enabled=false。
複雑な列タイプ
/**LOCATION: 対応するcosストレージディレクトリを指しますその他の部分はそのまま保持します*/CREATE EXTERNAL TABLE dlc_db.orc_demo_with_complex_type(col_bigint bigint COMMENT 'id number',col_int int,col_struct struct<x: double, y: double>,col_array array<struct<x: double, y: double>>,col_map map<struct<x: int>, struct<a: int>>,col_decimal DECIMAL(10,2),col_float FLOAT,col_double DOUBLE,col_string STRING,col_boolean BOOLEAN,col_date DATE,col_timestamp TIMESTAMP)PARTITIONED BY (`dt` string)STORED AS ORC LOCATION 'cosn://your_cos_location';
注意:
1. avro形式のデータソースは、map型とarray型のstruct構造のネストをサポートしていません。
2. avro形式のデータソースにおけるmap型フィールドのkeyは、string型のみサポートしています。
3. csv形式のデータソースでstruct、array、map型フィールドを使用する場合、エンジンがデータ形式に対して厳密な検証を行うため、以下のようなエラーが発生する可能性があります。
解決方法:エンジンの厳密な検証設定を解除し、エンジンの静的パラメータspark.sql.storeAssignmentPolicy=legacyを設定します。
複雑なパーティションタイプ
1. LOCATION: 対応するcos上のストレージパスに変更する必要があります
2. サポートされているパーティションフィールドのタイプは、TINYINT、SMALLINT、INT、BIGINT、DECIMAL、FLOAT(非推奨、DECIMALの使用を推奨)、DOUBLE(非推奨、DECIMALの使用を推奨)、STRING、BOOLEAN、DATE、TIMESTAMPです。
CREATE EXTERNAL TABLE dlc_db.orc_demo_with_complex_partition(col_int int)PARTITIONED BY (pt_tinyint TINYINT,pt_smallint SMALLINT,pt_decimal DECIMAL(10,2),pt_string STRING,pt_date DATE,pt_timestamp TIMESTAMP )STORED AS ORC LOCATION 'cosn://lcl-bucket-1305424723/dlc/orc_demo_with_complex_partition/';
注意:
hiveタイプのテーブルパーティション名の合計は767文字を超えることはできません。
メタデータは大文字と小文字を区別しません
メタデータのテーブル名と列名は使用時に大文字と小文字を区別しませんが、データ管理インターフェースに表示する際は作成時の元の大文字小文字形式が保持されます。
フィードバック