PySpark依存パッケージ管理
Download
フォーカスモード
フォントサイズ
現在のDLCのPySpark基本実行環境ではPython=3.9.2を使用しています。
SparkジョブのPython依存関係は以下の2つの方法で利用できます:
1.
--py-filesを使用して依存モジュールやファイルを指定します。2.
--archivesを使用して仮想環境を指定します。もしモジュールやファイルが純粋なPythonで実装されている場合、
--py-filesを使用して指定することをお勧めします。--archivesを使用すると、開発テスト環境全体を直接パッケージ化して使用できます。この方法はC関連の依存関係のコンパイルインストールをサポートしており、依存環境が比較的複雑な場合に推奨されます。説明:
上記の2つの方法は、ご要望に応じて同時に使用できます。
--py-filesを使用して依存パッケージを指定します。
この方法は、Cの依存関係を含まない純粋なPythonで実装されたモジュールやファイルに適しています。
ステップ1:モジュール/ファイルをパッケージ化する
PyPI外部パッケージは、ローカル環境でpipコマンドを使用してインストールし、一般的な依存関係をパッケージ化する必要があります。依存パッケージは純粋なPythonで実装され、C関連ライブラリに依存しないことが求められます。
pip install -i https://mirrors.tencent.com/pypi/simple/ <packages...> -t depcd depzip -r ../dep.zip .
単一ファイルモジュール(funtions.py)とカスタムPythonモジュールは、上記の方法でパッケージ化できます。ただし、カスタムPythonモジュールはPythonの公式要件に従って標準化する必要があることに注意してください。詳細はPython公式ドキュメントPython Packaging User Guideを参照してください。
ステップ2:パッケージ化されたモジュールを導入する
データレイク DLC コンソールのデータジョブモジュールで新しいジョブを作成します。
--py-filesパラメータでパッケージ化されたdep.zipファイルを導入します。このファイルはCOSにアップロードするか、ローカルからアップロードする方法で導入できます。
仮想環境を使用する
仮想環境は、一部のPython依存パッケージがCに依存する問題を解決できます。ユーザーは必要に応じて、依存パッケージをコンパイルして仮想環境にインストールし、その後仮想環境全体をアップロードできます。
C関連の依存関係はコンパイルとインストールを伴うため、x86アーキテクチャのマシン、Debian 11(bullseye)システム、Python = 3.9.2環境を使用してパッケージ化することを推奨します。
手順1:仮想環境をパッケージ化する
仮想環境をパッケージ化するには、Venvを使用する方法とCondaを使用する方法の2通りがあります。
1. Venvを使用してパッケージ化する
python3 -m venv pyvenvsource pyvenv/bin/activate(pyvenv)> pip3 install -i [https://mirrors.tencent.com/pypi/simple/](https://mirrors.tencent.com/pypi/simple/) packages(pyvenv)> deactivatetar czvf pyvenv.tar.gz pyvenv/
2. Condaを使用してパッケージ化します。
conda create -y -n pyspark_env conda-pack <packages...> python=<3.9.x>conda activate pyspark_envconda pack -f -o pyspark_env.tar.gz
パッケージ化が完了したら、パッケージ化された仮想環境パッケージ
pyvenv.tar.gzをcosにアップロードします。注意:
tarコマンドを使用してパッケージ化してください。
3. パッケージ化スクリプトを使用します。
パッケージ化スクリプトを使用するには、docker環境をインストールする必要があります。現在、Linux/mac環境をサポートしています。
bash pyspark_env_builder.sh -hUsage:pyspark-env-builder.sh [-r] [-n] [-o] [-h]-r ARG, the requirements for python dependency.-n ARG, the name for the virtual environment.-o ARG, the output directory. [default:current directory]-h, print the help info.
パラメータ | 説明 |
-r | requirements.txtの場所を指定 |
-n | 仮想環境の名前を指定、デフォルトは py3env |
-o | 仮想環境の保存先ローカルディレクトリを指定、デフォルトは現在のディレクトリ |
-h | ヘルプ情報を印刷 |
# requirement.txtrequests以下のコマンドを実行してくださいbash pyspark_env_builder.sh -r requirement.txt -n py3env
スクリプトの実行が完了したら、現在のディレクトリでpy3env.tar.gzを取得し、そのファイルをcosにアップロードできます。
ステップ2:仮想環境を指定する
データレイク DLC コンソールのデータジョブモジュールで新しいジョブを作成し、以下のスクリーンショットを参考に操作してください。
1.
--archivesパラメータに仮想環境の完全なパスを入力し、#の後ろは解凍フォルダ名です。
注意:
「#」は解凍先ディレクトリを指定するために使用されます。解凍先ディレクトリは後続の実行環境パラメータ設定に影響を与えます。
2.
--configパラメータで実行環境パラメータを指定します。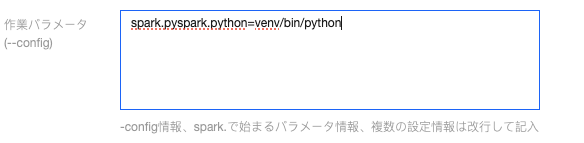
Venv パッケージ方式を使用する場合は、
spark.pyspark.python = venv/pyspark_venv/bin/python3を設定してください。Conda パッケージ方式を使用する場合は、
spark.pyspark.python = venv/bin/python3を設定してください。スクリプトパッケージ方式を使用する場合は、
spark.pyspark.python = venv/bin/python3を設定してください。説明:
venvとcondaはパッケージ方式が異なるため、ディレクトリ階層が異なります。具体的には、.tar.gzを解凍してpythonファイルの相対パスを確認できます。
フィードバック