新建任务
Download
聚焦模式
字号
本文为您介绍如何新建定时 SQL 分析任务。
前提条件
已开通日志服务,源日志主题开启 键值索引。
确保当前操作账号拥有配置定时 SQL 分析的权限,详情请参见 CLS 访问策略模板。
操作步骤
1. 登录 日志服务控制台,在左侧导航栏中选择定时 SQL 分析,单击新建。
2. 配置定时 SQL 分析任务,其中写入目标可分为指标主题和日志主题。
写入目标为日志主题:用于日志过滤、日志预聚合等场景。
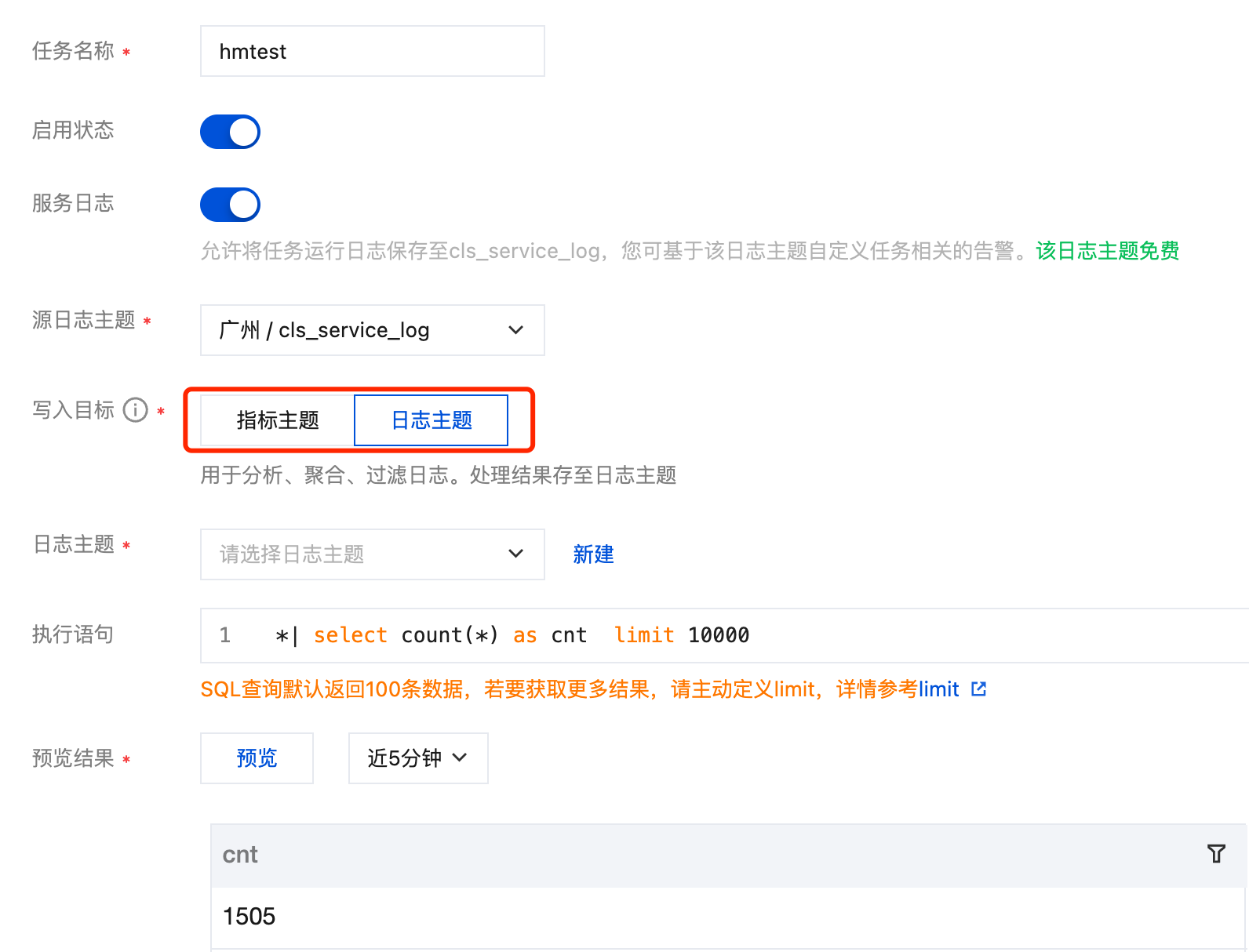
使用场景:
预聚合。例如:日志10秒上报一次,如果业务需要查询60天的数据:
*| select count(*) group by ip, request_method,IP 在60天内可能超出1亿条数据,由于维度太高,会查询失败。那么可以使用日志转指标,将日志预聚合为分钟级别的指标数据,然后再查询聚合后的指标主题就不会再超时。转指标存储的优势:
查询费用低:指标仅收取存储和写流量费,无索引流量和索引存储费用(日志有)。同等数据量下,指标查询费用更低,请参见 产品定价。
存储费用:尤其针对需要查询长周期时间范围的业务,转指标后,可将原始 日志沉降 至低频存储(低频不支持 SQL,可检索),进一步节约日志存储费。
查询速度更快。请参见 日志转指标。
配置项:
配置项 | 说明 |
任务名称 | 定时 SQL 的任务名称,长度255字符,下划线,英文字母和数字组合。 |
启用状态 | 默认开启,开启/关闭任务。 |
服务日志 | 开启/关闭,打开之后,定时 SQL 任务运行的监控指标将写入服务日志,例如单次查询结果、查询时间等。 |
源日志主题 | 定时 SQL 任务的输入,即需要转换为指标的原始日志所在的日志主题。 |
写入目标 | 指标主题/日志主题。 |
执行语句 | * | select avg(cpu_usage)as cpu_usage ,avg(mem_usage) as mem_usage,namespace,cluster group by namespace,cluster limit 10000说明: 如果您修改了 SQL 语句,请单击预览,刷新 SQL 查询结果。 查询结果数量将按照您指定的 limit 返回,如需返回全量数据,请单击执行语句右侧的配置按钮,关闭 SQL 结果默认 Limit 开关,然后删除执行语句中的 limit。 |
指标名称 | 多选,一般为数值类型。从下拉列表中选择字段作为指标名称,例如上面的例子中,cpu_usage 和 mem_usage 为指标名称,其值为指标值。 |
指标维度 | 多选,不可选择时间类型的字段作为指标维度。 从下拉列表中选择字段作为指标维度,例如上面的例子中,namespace、cluster 为维度,其值为维度值。可理解为按照不同的 cluster 和 namespace 组合来查看 cpu_usage 和 mem_usage。指标维度一般就是您的 SQL 语句中 group by 的维度字段(时间类型字段除外)。 |
自定义维度 | 新增指标的维度,维度值是静态的。例如:您原来的指标维度为 go_gc_duration_seconds{job="prometheus",quantile="0"}添加自定义维度 tcloud_region_name="ap-guangzhou" 之后,维度变为:go_gc_duration_seconds{job="prometheus", quantile="0",tcloud_region_name="ap-guangzhou" } |
时间戳 | 默认值:指标的默认时间戳为查询时间窗口的左侧时间,例如 查询时间窗口为5月7日00:00:00 - 5月7日00:10:00,那么该次计算生成的指标时间戳为5月7日00:00:00。 自定义时间戳:如果您在 SQL 语句中自定义了时间类型的字段,可以在下拉列表中,选择该字段为指标的指标戳。如果没有看到该时间类型字段,请单击 SQL 语句下方的预览,刷新下拉列表中的字段值。例如,您使用 检索分析语句 * | select count(*) as cnt,histogram(__TIMESTAMP__,INTERVAL 15 SECOND) as time group by time limit 100 每15秒计算一次日志条数,可以选择 time 字段为您的自定义时间戳。这样您在指标主题中,将每隔15秒生成一条指标数据。注意:自定义时间戳的间隔最小为15秒。 说明: 自定义时间戳支持选择 UNIX 时间、TimeStamp 的类型,精度为毫秒。例如:1629876543.123,2021-08-25T12:22:23.123+08:00。 自定义时间戳的最小间隔为15秒。例如15:00:00,15:00:15,15:00:30。 |
调度范围 (Scope) | 定时 SQL 任务处理的日志数据的范围,例如2023年1月1日00:00:00-2023年3月31日00:00:00的日志,如果结束时间不选择,表示任务将持续运行,将新采集的日志持续地转换为指标。 |
调度周期 | 取值范围1分钟 - 1440分钟,如您配置为 X,则意为每隔 X 分钟会发起一次日志查询,日志查询的结果将保存为指标。 推荐配置1分钟,更加及时的将日志转化为指标。 |
查询时间窗口 (Query Window) | 推荐配置 @m-1m ~ @m,即最近1分钟,每次查询一分钟的日志数据,并将其转化为指标。 注意: 转指标时,该参数切勿超过30分钟,否则可能导致转指标失败。 快速配置:如选择近5分钟,如果当前时间为17:30,那么查询时间窗口为17:25 - 17:30。 时间表达式:适用于相对时间的表达,如果指定时间表达式为 @m-10m 至 @m-5m,当前时间为17:30,那么查询时间窗口为17:20 - 17:25。 |
高级设置 | 查询延迟的时间,在控制台高级设置中,取值范围60秒 - 120秒。日志生成索引一般会有延迟,在索引生成之前,不可查询,因此设置60秒延迟查询,此时索引已生成(99.9%的索引数据将在5秒内生成)。 |
使用场景:
过滤日志:
*| SELECT ip where region="guangzhou" 注意:
定时 SQL 的执行会延迟1分钟,例如查询11:01-11:02的数据,查询会在11:03发起,且最多返回100W条数据,需评估是否符合您的场景。
预聚合:例如日志10秒上报一次,如果业务需要查询60天的数据:
*| SELECT ip , AVG(request_time) AS avg_request_time GROUP BY ip,IP 在60天内可能超出1亿条数据,由于维度太高,会查询失败。那么可以使用定时 SQL,将秒级别日志预聚合为分钟级别数据,然后再查询聚合后的数据就不会再超时。配置项:
配置项 | 说明 |
任务名称 | 定时 SQL 任务的名称,长度255字符,下划线,英文字母和数字组合。 |
启用状态 | 默认开启,开启/关闭任务。 |
服务日志 | 开启/关闭,打开之后,定时 SQL 任务运行的监控指标将写入服务日志,例如单次查询结果、查询时间等。 |
源日志主题 | 定时 SQL 任务的输入,需要被处理的原始日志。 |
写入目标 | 定时 SQL 任务的输出(1个),选择日志主题,建议提前配置目标主题的索引。 |
执行语句 | 使用 SQL 语句 对原始日志进行统计,例如:调度周期配置为1分钟,查询时间窗口配置为1小时,SQL 语句为 *| select sum(active_user) as hourly_active_user limit 10000,表示为每分钟统计一次近一小时的活跃客户数。说明: 如果您修改了 SQL 语句,请单击预览,刷新 SQL 查询结果。 查询结果数量将按照您指定的 limit 返回,如需返回全量数据,请单击执行语句右侧的配置按钮,关闭 SQL 结果默认 Limit 开关,然后删除执行语句中的 limit。 |
调度范围 (Scope) | 定时 SQL 任务处理的日志数据的范围,例如2023年1月1日 00:00:00-2023年3月31日00:00:00的日志,如果不指定结束时间,则默认持续运行。 |
调度周期 | 取值范围1分钟 - 1440分钟,如您配置为1分钟,则意为每隔 1 分钟会发起一次日志查询。 |
查询时间窗口 (Query Window) | 查询时间窗口,单次日志查询的时间窗口. 快速配置:如选择近5分钟,如果当前时间为17:30,那么查询时间窗口为17:25-17:30。 时间表达式:适用于相对时间的表达,如果指定时间表达式为 @m-10m 至 @m-5m,当前时间为17:30,那么查询时间窗口为17:20 - 17:25。 |
高级设置 | 查询延迟的时间,在控制台高级设置中,取值范围60秒 - 120秒。日志生成索引一般会有延迟,在索引生成之前,不可查询,因此设置60秒延迟查询,此时索引已生成(99.9%的索引数据将在5秒内生成)。 |
时间表达式语法
您在创建定时 SQL 分析时,可指定 SQL 时间窗口。定时 SQL 任务运行时,仅查询该 SQL 时间窗口内的日志。如下内容介绍 SQL 时间窗口相关的时间表达式语法。
操作符 | 说明 |
+ | 加号 |
- | 减号 |
@ | 取整操作符,根据时间向下取整。例如以小时为单位对时间01:40进行取整,取整后为01:00。 |
时间单位 | 说明 |
h | 时 |
m | 分 |
s | 秒 |
示例
时间表达式 | 说明 |
@m-15m 到 @m-5m | 先减15分钟再向下取整到分钟。 例如,创建定时 SQL 任务时,配置调度间隔为每天00:00,延迟执行为30秒,SQL 时间窗口为[@m-15m,@m-5m),则表示在00:00:30时刻执行 SQL 任务,分析[23:45~23:55)期间的数据。 |
@h-1h 到 @h | 先减1小时再向下取整到小时。 例如,创建定时 SQL 任务时,配置调度间隔为每天00:00,延迟执行为30秒,SQL 时间窗口为[@h-1h@h,@m-5m),则表示在00:00:30时刻执行 SQL 任务,分析[23:00~23:55)期间的数据。 |
@h-12h+5m 到 @m-5m | 先减12小时再加5分钟,即减11小时55分钟。 例如,创建定时 SQL 任务时,配置调度间隔为每天00:00,延迟执行为30秒,SQL 时间窗口为[@h-12h+5m,@m-5m),则表示在00:00:30时刻执行 SQL 任务,分析[12:05~23:55)期间的数据。 |
文档反馈