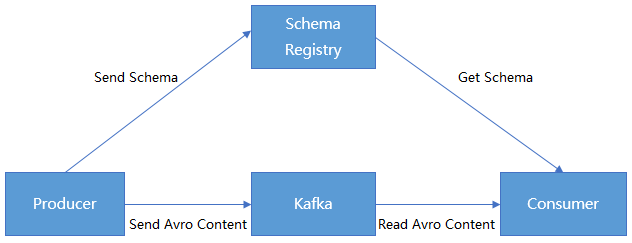
We can serialize/deserialize classes by using Avro APIs or the Twitter Bijection class library, but the disadvantage of the two methods is that the Kafka record size will multiply as each record must be embedded with a schema. However, the schema is required for reading the records.
TDMQ for CKafka (CKafka) makes it possible for data to share one schema by registering the content of the schema in Confluent Schema Registry. Kafka producers and consumers can implement serialization/deserialization by identifying the schema content in Confluent Schema Registry.
2. In the left sidebar, select Instance List and click the ID of the target instance to go to the basic instance information page.
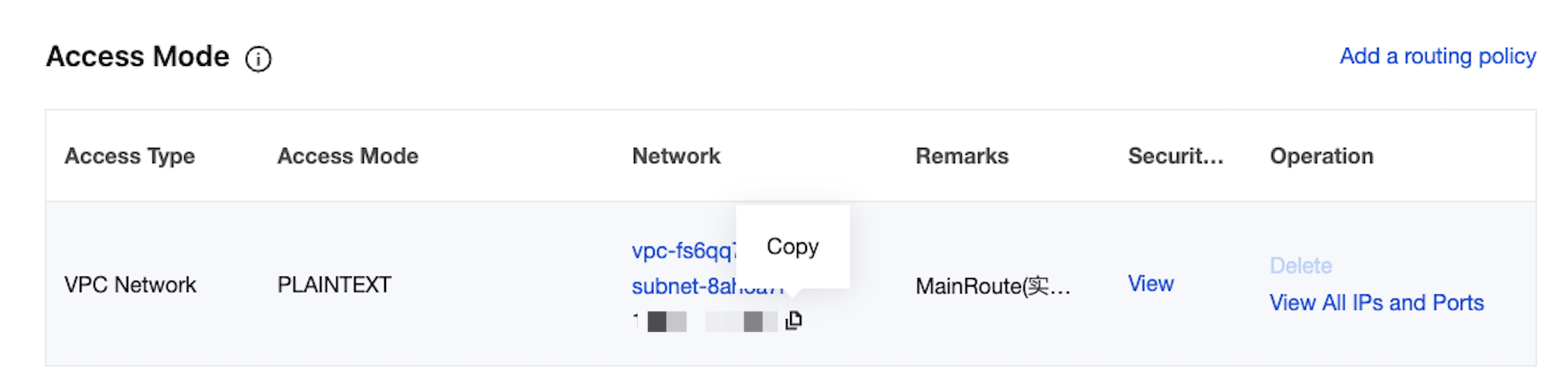
3. In the Access Mode module on the basic instance information page, you can obtain the access address of the instance.
4. Enable automatic topic creation in the Automatic Topic Creation module.
Note
Automatic topic creation must be enabled, as a topic named schemas will be automatically created when OSs are started.
Step 2: Preparing Confluent Configurations
1. Modify the server address and other information in the OSs configuration file.
The configuration information of the PLAINTEXT access method is as follows:
kafkastore.bootstrap.servers=PLAINTEXT://xxxx
kafkastore.topic=schemas
debug=true
The configuration information of the SASL_PLAINTEXT access method is as follows:
1. Register the schema in the topic named test.
The script below is an example of registering a schema by calling an API with the curl command in the environment deployed in Schema Registry.
curl -X POST -H "Content-Type: application/vnd.schemaregistry.v1+json" \\
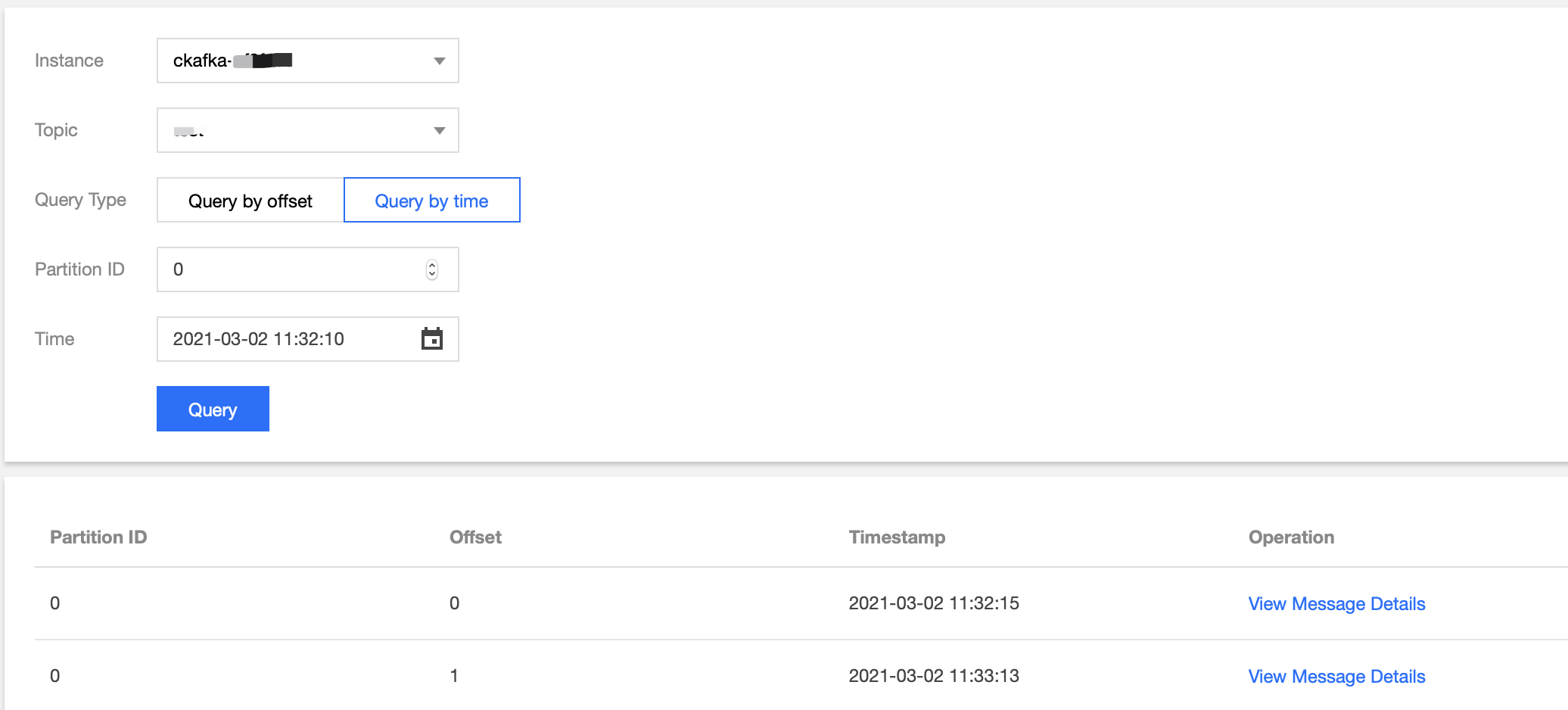
After running the script for a while, go to the CKafka console, select the Topic Management tab, select the target topic, and choose More > Message Query to view the message just sent.
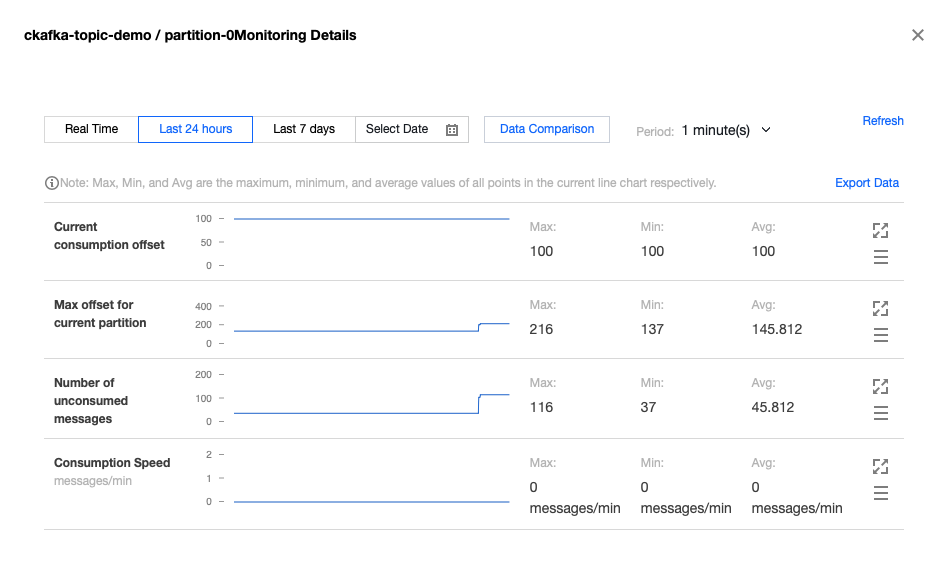
On the Consumer Group tab page in the CKafka console, select the consumer group named schema, enter the topic name, and click View Consumer Details to view the consumption details.
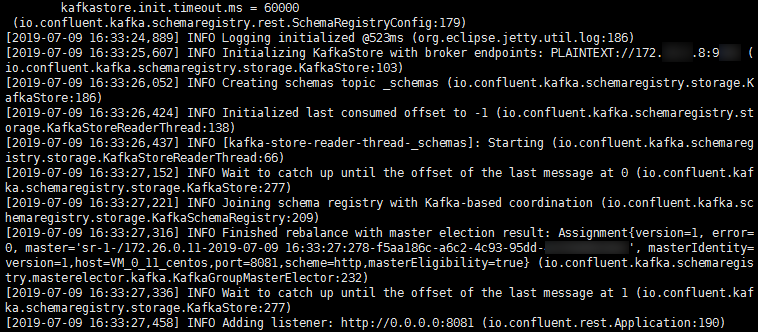
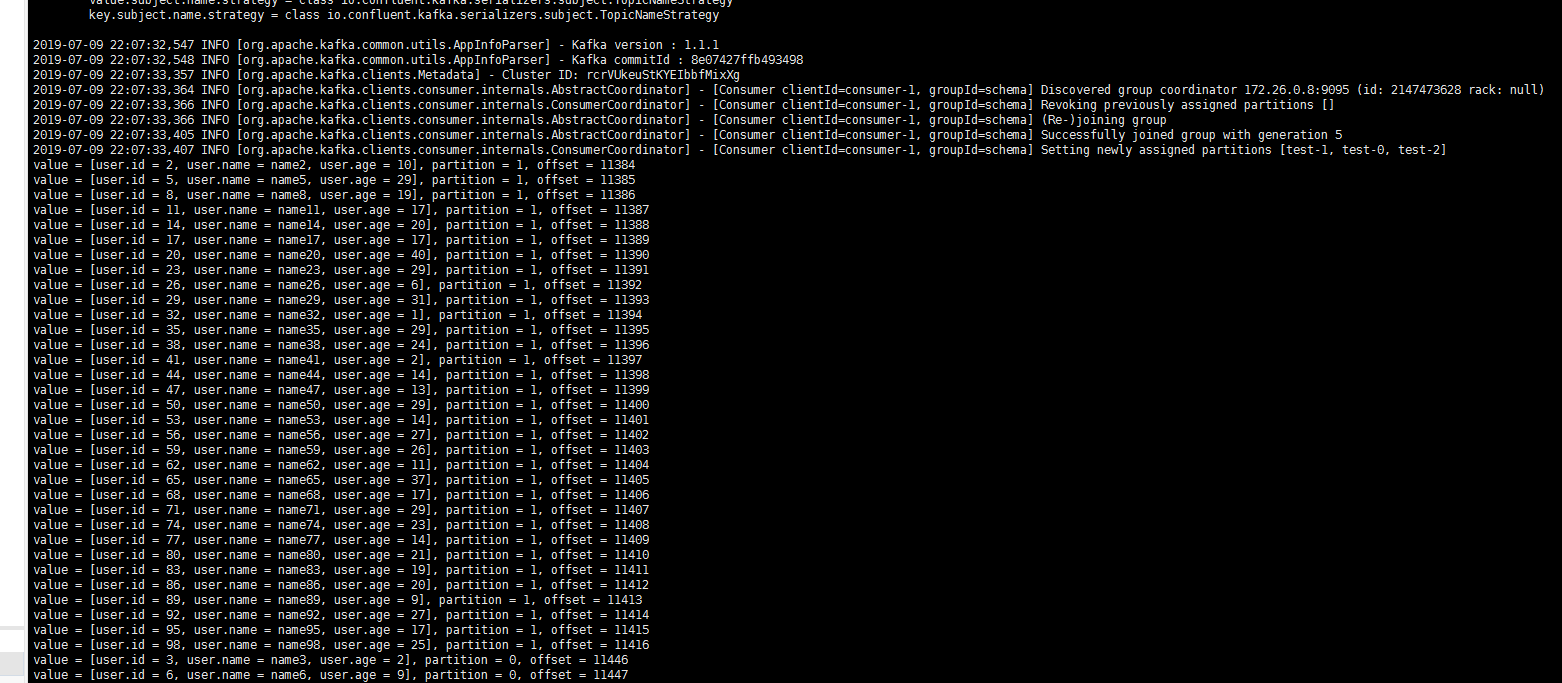
Start the consumer for consumption. Below is a screenshot of the consumption log: