監視指標の簡略化
Download
フォーカスモード
フォントサイズ
注意
TMPは2022年10月27日より、無料指標の無料保存期間を15日間に調整しました。保存期間が15日を超えたインスタンスについては、超過日数に応じて無料指標の保存料金がかかります。具体的な課金ルールについては、課金説明をご参照ください。
このドキュメントでは、Prometheus監視サービスが収集する指標を簡略化し、不必要な料金がかからないようにする方法についてご説明します。
前提条件
監視データの収集項目の設定を行う前に、次の操作を完了する必要があります。
Prometheus監視インスタンスの作成に成功している必要があります。
監視したいクラスターを対応するインスタンスにバインドしている必要があります。
指標の簡略化
コンソール上での指標の簡略化
1. TKEコンソールにログインし、左側ナビゲーションバーのPrometheus監視を選択します。
2. 監視インスタンスリストページで、データ収集ルールを設定したいインスタンス名を選択し、そのインスタンス詳細ページに進みます。
3. 「クラスター監視」ページで、クラスター右側のデータ収集設定をクリックし、収集設定リストページに進みます。
4. 基本指標については製品化のページで収集対象の追加/削減を行うことができます。右側の「指標の詳細」をクリックします。
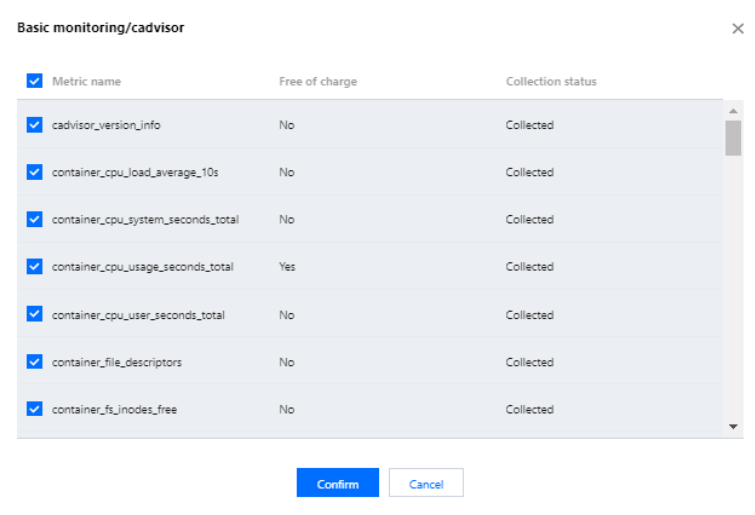
5. 以下のページで、各指標が無料かどうかを確認できます。チェックが入っている指標は、それらの指標を収集していることを表します。追加の料金がかからないようにするには、有料の指標のチェックを外すことをお勧めします。基本監視についてのみ、無料の監視指標をご提供しています。完全な無料指標の詳細については、従量課金無料指標をご参照ください。有料指標の計算の詳細については、Prometheus監視サービスの従量課金をご参照ください。
YAMLでの指標の簡略化
TMPの現在の課金方式は監視データのポイント数に応じた課金です。無駄なコストを最大限削減するために、収集の設定を最適化し、必要な指標のみを収集し、不必要な指標をフィルタリングすることで全体のレポート量を減らすことをお勧めします。詳細な課金方式および関連クラウドリソースの使用については、ドキュメントをご確認ください。
以下の手順では、カスタム指標のServiceMonitor、PodMonitor、およびネイティブJob内にフィルタリング設定を追加し、カスタム指標を簡略化する方法についてそれぞれご説明します。
1. TKEコンソールにログインし、左側ナビゲーションバーのPrometheus監視を選択します。
2. 監視インスタンスリストページで、データ収集ルールを設定したいインスタンス名を選択し、そのインスタンス詳細ページに進みます。
3. 「クラスター監視」ページで、クラスター右側のデータ収集設定をクリックし、収集設定リストページに進みます。
4. インスタンス右側の編集をクリックし、指標の詳細を確認します。
ServiceMonitorとPodMonitorのフィルタリング設定フィールドは同じです。ここではServiceMonitorを例にとります。
ServiceMonitorの例:
apiVersion: monitoring.coreos.com/v1kind: ServiceMonitormetadata:labels:app.kubernetes.io/name: kube-state-metricsapp.kubernetes.io/version: 1.9.7name: kube-state-metricsnamespace: kube-systemspec:endpoints:- bearerTokenSecret:key: ""interval: 15s # このパラメータは収集の頻度です。これを大きくすることでデータ保存料金を抑えることができます。例えば、重要でない指標は300sに変更すると、20倍の監視データ収集量を削減できますport: http-metricsscrapeTimeout: 15s # このパラメータは収集のタイムアウト時間です。Prometheusの設定が要求する収集タイムアウト時間は収集間隔より長くすることはできません。すなわち、scrapeTimeout <= intervalとなりますjobLabel: app.kubernetes.io/namenamespaceSelector: {}selector:matchLabels:app.kubernetes.io/name: kube-state-metrics
kube_node_infoとkube_node_roleの指標を収集したい場合は、ServiceMonitorのendpointsリストに、metricRelabelings フィールド設定を追加する必要があります。**metricRelabelings**であり、relabelingsではないことにご注意ください。
metricRelabelings追加の例:apiVersion: monitoring.coreos.com/v1kind: ServiceMonitormetadata:labels:app.kubernetes.io/name: kube-state-metricsapp.kubernetes.io/version: 1.9.7name: kube-state-metricsnamespace: kube-systemspec:endpoints:- bearerTokenSecret:key: ""interval: 15s # このパラメータは収集の頻度です。これを大きくすることでデータ保存料金を抑えることができます。例えば、重要でない指標は300sに変更すると、20倍の監視データ収集量を削減できますport: http-metricsscrapeTimeout: 15s# 下の4行を追加しました。metricRelabelings: # 収集した各ポイントに対しすべて次の処理を行います- sourceLabels: ["__name__"] # 検出したいlabel名です。__name__ が指標名を表します。またこのポイントが持つ任意のlabelとすることもできますregex: kube_node_info|kube_node_role # 上記のlabelがこの正規表現を満たすかどうかです。ここでは、__name__がkube_node_infoまたはkube_node_roleを満たすことが求められますaction: keep # ポイントが上記の条件を満たす場合は維持し、満たさない場合は自動的に破棄しますjobLabel: app.kubernetes.io/namenamespaceSelector: {}selector:
使用しているのがPrometheusネイティブのJobである場合は、次の方式を参照して指標のフィルタリングを行うことができます。
Jobの例:
scrape_configs:- job_name: job1scrape_interval: 15s # このパラメータは収集の頻度です。これを大きくすることでデータ保存料金を抑えることができます。例えば、重要でない指標は300sに変更すると、20倍の監視データ収集量を削減できますstatic_configs:- targets:- '1.1.1.1'
kube_node_infoとkube_node_roleの指標のみを収集したい場合は、metric_relabel_configs設定を追加する必要があります。**metric_relabel_configs**であり、relabel_configsではないことにご注意ください。
metric_relabel_configs追加の例:scrape_configs:- job_name: job1scrape_interval: 15s # このパラメータは収集の頻度です。これを大きくすることでデータ保存料金を抑えることができます。例えば、重要でない指標は300sに変更すると、20倍の監視データ収集量を削減できますstatic_configs:- targets:- '1.1.1.1'# 下の4行を追加しました。metric_relabel_configs: # 収集した各ポイントに対しすべて次の処理を行います- source_labels: ["__name__"] # 検出したいlabel名です。__name__ が指標名を表します。またこのポイントが持つ任意のlabelとすることもできますregex: kube_node_info|kube_node_role # 上記のlabelがこの正規表現を満たすかどうかです。ここでは、__name__がkube_node_infoまたはkube_node_roleを満たすことが求められますaction: keep # ポイントが上記の条件を満たす場合は維持し、満たさない場合は自動的に破棄します
5. OKをクリックします。
一部の収集対象を無効にする
ネームスペース全体の監視を無効にする
TMPにクラスターをバインドすると、クラスター内のすべてのServiceMonitorとPodMonitorがデフォルトで管理下に入ります。あるネームスペース下の監視を無効にしたい場合は、指定のネームスペースにlabel:
tps-skip-monitor: "true"を追加することができます。labelの操作に関しては、こちらを参照してください。一部の収集対象を無効にする
TMPはユーザーのクラスター内にServiceMonitorおよびPodMonitorタイプのCRDリソースを作成することで監視データの収集を行います。指定のServiceMonitorとPodMonitorの収集を無効にしたい場合は、これらのCRDリソースにlabel:
tps-skip-monitor: "true"を追加することができます。labelの操作に関しては、こちらを参照してください。フィードバック