数据加工概述
Download
聚焦模式
字号
数据加工
提供对日志数据的过滤、清洗、脱敏、富化、分发等能力。按照数据加工在数据链路中的位置、source(数据源)和sink(结果保存)不同,当前可支持以下几种数据处理的场景:
场景 | 说明 |
 | 日志采集-加工-日志主题: 日志采集至 CLS,先经过数据加工(过滤、结构化),再写入日志主题。如图,数据加工在数据链路中处于日志主题之前,称之为前置数据加工。 在前置数据加工中做 日志过滤,可有效降低日志写流量、索引流量、索引存储量、日志存储量; 在前置数据加工中做 日志结构化,开启键值索引后,可使用 SQL 对日志进行分析、配置仪表盘和告警。 |
 | 日志主题-加工-固定日志主题: |
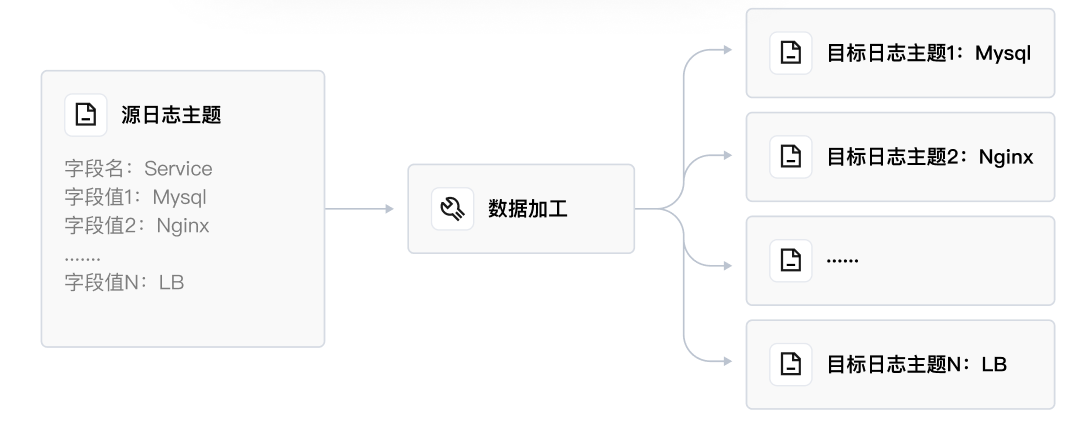 | 日志主题-加工-动态日志主题: 按照源日志主题的字段值,动态地创建日志主题,并将相关日志分发至对应的日志主题中。例如源日志主题中有一个字段 Service,有"Mysql"、"Nginx"、"LB"等值,CLS 可以自动创建名字为 Mysql、Nginx、LB 等的日志主题,并将相关日志写入以上主题中。 |
基本概念
功能特性
提取结构化的数据。方便后续 BI 分析、生成监控图表(Dashboard)等。如果您的原始日志不是结构化数据,则无法进行 SQL 计算,也意味着无法对日志进行 OLAP 分析、使用 CLS 仪表盘(基于 SQL 结果绘制图表)等。所以建议您使用数据加工来将非结构化的数据转为结构化的数据。如果您的日志是有规律的,也可以在日志采集时提取结构化数据,请参见 完全正则格式(单行)或者 分隔符格式。与采集侧相比,数据加工提供更为复杂的结构化处理逻辑。
日志过滤。节约后续使用成本。丢弃不需要的日志数据,节约云上的存储成本和流量成本。例如后续您可能将日志投递到腾讯云 COS、Ckafka,可以有效节约投递的流量。
敏感数据脱敏。例如:将身份证、手机号码等信息脱敏。
日志分发。例如:按照日志级别:ERROR、WARNING、INFO 将日志分类,然后分发到不同的日志主题。
产品优势
简单易用,对数据分析师、运维工程师尤为友好。提供开箱即用的函数无需购置、配置、运维 Flink 集群,只需要使用我们封装的 DSL 函数就可以实现海量日志的流处理,包括清洗过滤、脱敏、结构化、分发等,详情请参见 函数总览。
高吞吐实时日志数据流处理。加工效率高(毫秒处理延时)、吞吐高,可达10-20MB/S/分区(源日志主题的分区)。
客户案例
数据清洗过滤:客户 A,丢弃无效日志,仅保留指定字段,补齐部分缺失的字段和字段值。当日志中没有 product_name、sales_manager 字段时,视为无效日志,丢弃该条日志。否则保留日志,并且只保留 price、sales_amount、discount 这三个字段。其它字段 drop 掉,如果该条日志缺失 discount 字段,那么新增这个字段,并给它赋一个默认值,例如“70%”。
数据转换:客户 B,原始日志中的字段值是 IP 地址,客户需要根据 IP,新增国家、城市的字段和值。例如2X0.18X.51.X5,新增字段国家:中国,城市:北京。将 UNIX 时间戳转换为北京时间,例如1675826327,转化为2023/2/8 11:18:47。
日志分类投递:客户 C,原始日志是多层级 JSON,JSON 中还包括了 Array 数组,客户 C 使用数据加工将多层级 JSON 的指定节点的数组提取出来作为字段值,例如从 Array[0]中提取 Auth 字段的值,然后根据 Auth 字段的值,对日志数据进行分发。当值为“SASL”时,投递到目标主题 A;当值为“Kerberos”时,投递到目标主题 B;当值为“SSL”时,投递到目标主题 C。
日志结构化:客户 D,原始日志
"2021-12-02 14:33:35.022 [1] INFO org.apache.Load - Response:status: 200, resp msg: OK"通过数据加工完成结构化,结果为 log_time:2021-12-02 14:33:35.022, loglevel:info, status:200。费用说明
规格与限制
文档反馈